An analogy to understand supercomputers

What is a Supercomputer ?
Supercomputing is, before anything, a stack of many expertises: modeling, applied mathematics, computer science, hardware, cooling, and many more. Therefore, an “expert of supercomputing” is actually limited to one fraction of it.
For example, a hardware specialist knows nothing about the dire consequences of underestimating the diameter of a droplet in a Lagrangian liquid-phase model. It is not intuitive that getting a drop size wrong by a factor of two can increase the size of the simulation by a factor of 8. On the other hand, the physical modeling specialist will not take time to optimize its computation so it fits in the cache – although it can generate speedup of a factor 2.
This “cultural gap” is especially pronounced at the frontier between software people and hardware people. We introduce here an analogy that should help software people cross this frontier and perform better on the available hardware.
The analogy
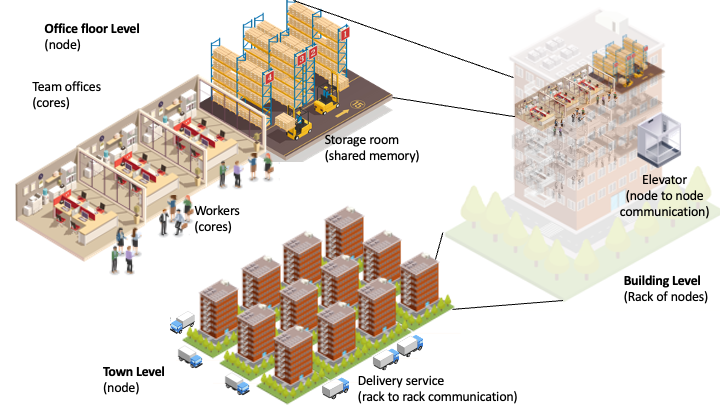
Imagine a town made only of small offices. An entire town of similar buildings dedicated to computing on demand. Each building is a collection of office floors (the computing nodes). Data moves between buildings with a fast delivery service, and inside buildings through faster elevators (node to node communication).
Now, each office floor has several offices (the processors) and shared storage rooms (the node memory). And each office hosts a team of workers (the cores).
Contractors in the need of computation book several floors, with the associated workers and the storage, for a limited period of time. When the period starts, data is supplied to the different floors to be processed, and results are sent back:
If you want to dive deeper in this image, let’s meet a worker. Let’s meet Bob:
Bob leads an exciting life in SiliconCity, the supercomputer town. Every day he wakes up to the hum of servers and the whir of cooling fans, ready to tackle the toughest computational challenges that come his way.
Bob works closely with his teammates Linda, Josh, and Michele, all members of the same processor team, the team “A”. They are an inseparable group, united by their love of fast processors, complex algorithms, and strong coffee.
Bob and his team love to complain about the two other processor teams, currently slacking off. Indeed, lately they are the only team working. A weird contractor booked this floor, but asked only team “A” on the job. “Probably a test run” said Linda, their senior.
They also grumble about the inconvenience of having to travel to another building just to get some data, but they know that it’s bound to happen sometimes. Maybe the contractor does not care about rack-to-rack communication. Maybe he is not even aware of the cost. Despite the challenges, they are determined to get the job done.
As Bob and Michele wrap up their work for the day, they chat about the GPU teams working in the next building.
“Those GPU people are something else,” Michele says with a smirk. “They can process a hundred of boxes while I can do only one, but they are sooo dumb sometimes.”
Bob chuckles in agreement. “I know, right ! And did you see that they always need CPUs like us to handle more complex stuff?”
Michele nods in understanding. “I guess that’s why we’re called the ‘central processor unit’, right? We may not be the fastest, but without us, nothing happens.”
Team A works late into the night, fueled by pizza and energy drinks. And as they shut down their computers and head home, they know that they’ll be back the next day to tackle whatever computational challenges come their way.
Expert’s Corner: Application to a Real Computer
Our expert readers might prefer a more applied illustration, so let us take a real-life example. In our laboratory, we have a supercomputer called “Kraken”, with 10204 cores for a total power of 1 Petaflops (10^15 Floating Operations Per Second). In the main scalar partition, there are 185 nodes “Skylake” containing 2 processors of 18 cores. These are usually shown as follows.
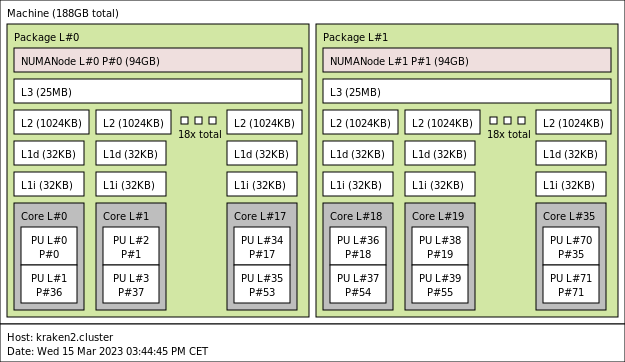
Now if we apply our analogy, this is how a “Skylake” node of kraken would look like: a floor with two aisles (#0 and #1), each with a shared storage room (Numanode) , an open space of 18 workers, and a shared forklift. There are 185 floors like this, totalling 6680 workers, scattered in 47 four-storey buildings.
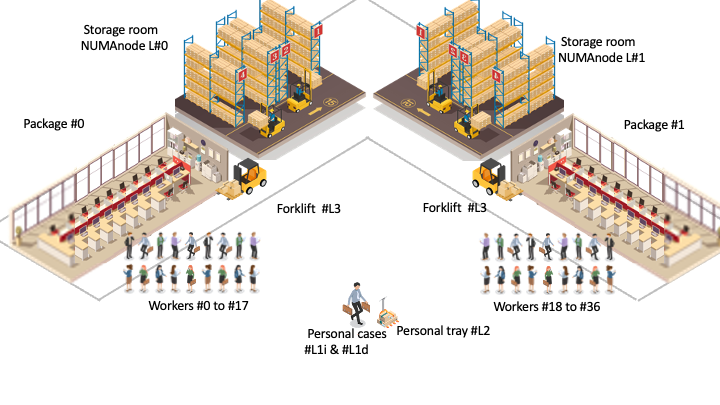
Note the intermediate “data carriers” helping the workers to move data around between the main “storage rooms” and their desk: a forklift shared by all the workers of a processor (L3 cache); a personal tray (L2 cache) and two personal cases (L1d and L2i) for each worker.
Users and programmers have very little control, if any, on what is happening at the cache levels. If you are not an expert, do not worry about these details for now. Just focus on the concepts of worker (core) and floor (node).
More About the Core
The core is your most atomic worker, like a basic office employee. Let us say data is a random integer number, e.g. 42. We put this 42 in a box and mail it to our worker in the morning, among many other boxes. The worker gets the box, opens it, performs an operation on the content (e.g. +1) and mails the result 43 back (yipee, we got a loop counter updated!).
Let’s crank up the difficulty. Imagine that your data is the value of the arctic ice surface at the beginning of each decade, expressed in millions of km2:
|
Year |
1980 |
1990 |
2000 |
2010 |
2020 |
|
Surface [Km2] |
7 |
6.1 |
6.2 |
5 |
4.5 |
We now ask the workers to look at the difference with the decade before. Now, when a worker gets box 2010, opens it and reads 5, he also needs box 2000 to perform the calculation. Either box 2000 is located in his own batch of boxes, or it is in the share of another worker. This is why workers should exchange some data while working. This worker-to-worker kind of communication is often a speed bottleneck. If both workers share the same open space, then the cost is negligible. However, if they are further away, say, in different buildings, the communication cost is increased by orders of magnitude and becomes a performance concern.
The workers are grouped in teams called “processors”: The most common team is polyvalent and involves 10 to 100 workers of the same sort. This is called a CPU (Central Processing Unit). There are also larger and more specialized teams, involving thousands of identical workers, which are called GP-GPU, or GPU for short (General Purpose Graphical Processing Units). These are “accelerators”. While they can do (+1) on thousands of boxes at the same time, they cannot read text nor can they archive anything. Their limitations explain why you cannot see GPU working without the cooperation of CPU.
More About the Nodes
A node is one floor of an office building, which hosts several teams of workers and their material. Each floor features one open space room per team, which has its own local storage, and shared storage accessible to all teams.
Group these buildings with an efficient delivery system and you get the town called “supercomputer”. The fastest communication is within the same team. Communication between teams on the same floor is slower, communication between different floors is even slower, and so on. The slowest communication is between far away buildings. The closest the data is to the workers, the more efficient they will be.
Usually a node is dedicated to a single mission for a single customer for many days. Recently, as nodes have been growing more powerful, it has been possible to work for several customers at the same time. This is called “node sharing”. However, most computations are expressed in non-shared nodes.
Grouping nodes
The way nodes are grouped on a machine varies a lot, creating great confusion in the terms. There are always a group of nodes in a “rack”. According to our humble experience, whether this “rack” refers to a whole “cabinet” (something looking like a fridge) or something smaller will depend on the machine architecture, and the naming habits built by the computer team.
You can read further about the profusion of terms in this “Router switch” topic: Rack Server Vs Blade Server.
In any case, node-to-node communication is slower than in-node communication, and depending on the way they are interlinked, even bigger delays can appear between physically far away nodes. In the remainder of this text let us name this potentially stronger bottleneck as the “rack-to-rack” communication cost.
Some Applications of this Analogy:
Weak Scaling versus Strong Scaling
Weak scaling is when ten times more workers are used to perform ten times more work for the same duration. In this case, at the worker’s level, the share of boxes per day is not changing at all, and it is quite easy to show good results from your manpower.
Strong scaling on the other hand, is when ten times more workers are used to perform the work ten times faster. As the number of boxes per worker decreases, each worker will eventually ask partners for the missing data. The communication cost increases, inevitably leading to performance issues.
The Importance of being Constant
Some users wonder sometimes:
It is crazy, every time I run a simulation, performance changes! I swear it is the same run though!
When someone asks for resources, the set of nodes selected is taken from the currently available free nodes. As a consequence, the same run will be performed twice by a different set of nodes. Thus it becomes a matter of luck, on machines with a clear “rack-to-rack” bottleneck. Assuming that the user takes four nodes from up to two cabinets with a strong delay of communication between the cabinets, the runs with nodes from the same cabinet will be significantly faster.
Benchmarks can specify the set of nodes to measure repeatable performance on such machines. However, this is not an option in production. The waiting time would be orders of magnitude bigger, and worse, if every user was forcing their node sets, the machine occupation would crumble.
The Importance of Filling the Cache
When an HPC expert says, while looking at the performance logs:
Nobody ever pays attention to the cache! That is not high performance computing any more!
The data has to fit in the storage. If the application provides too many boxes, they will not fit in the closest storage room, and the worker will have to fetch them from further away. On the other hand, if the application does not provide enough boxes to fill the storage, the worker will not work all day long. To sum it up, one must find an optimum balance between too many boxes and too few. It looks like an expert parameter to the end user, but this parameter can save a lot of computational time…
One Node to Rule them all
When an HPC expert says, after a dazzling HPC benchmark presentation:
Ok this is a nice speedup, but it was only shown at node scale.
In fact, if you limit yourself to work that can be done on a single floor, you avoid the speed bottleneck of node to node, and probably rack-to-rack communication. You are thus not tackling the hardest communication bottlenecks that come with larger computations.
The analogy of “workers in a building” illustrates the communication challenges caused by the logistics of moving data boxes to the employees’ desks and back. The extra-work to locate the needed data in other buildings can dishearten HPC software makers. Some bit the bullet and focused on single node performance. This can prove to be very smart as the computational power of nodes is rising, and some compilers provide built-in features helping the work orchestration (e.g. Fortran CoArrays). Not mentioning this single-node aspect in a benchmark is bad, and is one of the tricks to fool the masses on HPC performance.
The Need of Automated Porting
“Porting” is the action of organizing the work between the available workers. When all the workers are gathered in identical teams, porting only consists in taking care of the communication bottleneck. However, the current tendency for HPC architecture is to increase the number and variety of workers in a single node, in order to increase the theoretical performance. As a consequence, the available hardware is getting less homogeneous and the work organization is getting more complicated.
This fuels – and is fueled by – the Machine Learning/Artificial Intelligence applications which need more specialized workers than the GPUs, like the TPUs (TensorProcessing units) which give lower precision for higher volume of computation.
The task of “porting” manually an existing software to a new architecture is getting harder with the heterogeneity of the hardware. This demands the creation of middle-layer software/languages between the software and its compiler, which automate a substantial part of the porting, such as OpenACC,Kokkos, SYCL or the older Legion.
All these middle layer softwares try to stay attuned to the present existing architecture trends, and to impose their own standard. However, as there is no standard on the heterogeneous hardware side, this competition will rage for some more years.
Take away
Let’s recap the different ideas we introduced here:
- A core is the most atomic worker
- A processor is a team of workers, either CPU or GPU. It has its own storage, and access to the node’s shared storage as well.
- A node is a floor in a building, with several teams working separately.
- The building is, to simplify, a rack. Going further in the analogy depends on the machine.
- The cluster, or supercomputer, is the entire town of office buildings linked together by a delivery service.
Communications can happen at every level, but keep in mind that the closer it is to the core, the faster data is exchanged.