We can affirm with quite a certainty that future Exascale systems will be heterogeneous, including accelerators such as GPUs. We can also expect higher variability on the performance of the various computing devices engaged in a simulation; due to the explosion of the parallelism, or other technical aspects such as the hardware-enforced mechanisms to preserve the thermal design limits. In this context, dynamic load balancing (DLB) becomes a must for the parallel efficiency of any simulation code.
In the first year of the EXCELLERAT project, Alya has been provisioned with a distributed memory DLB mechanism, complementary to the node-level parallel performance strategy already in place. The kernel parts of the method are an efficient in-house SFC-based mesh practitioner and a redistribution module to migrate the simulation between two different partitions online. Those are used to correct the partition according to runtime measurements.
We have focused on maximising the parallel performance of the mesh partition process to minimise the overhead of the load balancing. Our approach was presented in the SC19 conference in Denver [1]. We demonstrated that our software can partition a 250M elements mesh of an Airplane with 0.08 sec using 128 nodes (6144 CPU-cores) of the MareNostrum V supercomputer – ten times faster compared to the Zoltan software from Sandia National Laboratories.
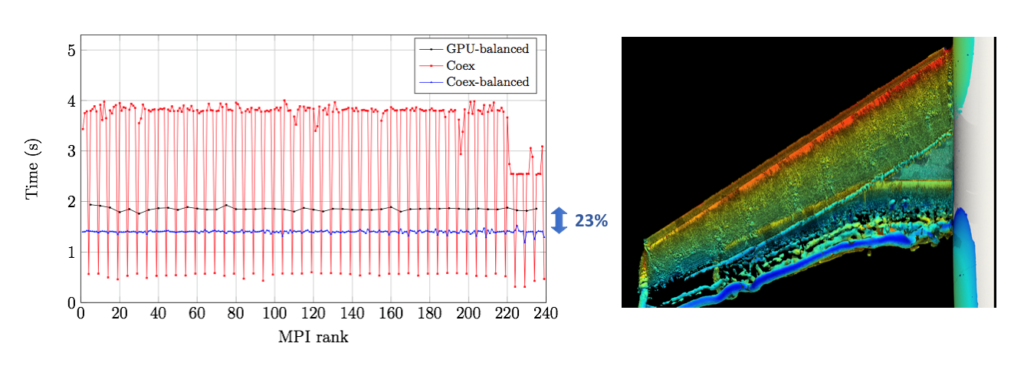
We then applied all this technology to perform simulations on the heterogeneous POWER9 cluster installed at the Barcelona Supercomputing Center, with an architecture very similar to that of the Summit supercomputer from the Oak Ridge National Laboratory – ranked first in the top500 list. In the BSC POWER9 cluster, which has 4 NVIDIA P100 GPUS per node, we demonstrated that we could perform a well-balanced co-execution using both the CPUs and GPUs simultaneously, being 23% faster than using only the GPUs. In practice, this represents a performance boost equivalent to attaching an additional GPU per node. This research was published at the Future Generation Computer Systems journal [2] where a full analysis of the code performance is given. Sample results of the elapsed time per MPI Rank is given in Figure 1 (left), while a snaphsot of Q-vorticity along the wing is shown in Figure 1 (right).
[1] R. Borrell, G Oyarzun, et al. Proceedings of ScalA 2019: 10th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems – Held in conjunction with SC 2019: The International Conference for High Performance Computing, Networking, Storage and Analysis, 8948628, pp. 72-78, 2019.
[2] R. Borrell, D. Dosimont et al. Heterogeneous CPU/GPU co-execution of CFD simulations on the POWER9 architecture: Application to airplane aerodynamics. Future Generation Computer Systems, (107): 31-4, 2020.