High performance Computing (HPC) has uses in a wide variety of fields, ranging from fundamental research to industrial design, as measured e.g. by the Technology Readiness Level. It involves actors in both scientific and the engineering communities. This document focuses on the latter, i.e. uses of HPC in industrial applications.
 The hardships of bringing a fancy bleeding edge HPC application in a competitive world.
The hardships of bringing a fancy bleeding edge HPC application in a competitive world.
Engineering workflows, which used to be pen and paper in the 20th century, now rely increasingly on Computer-Aided Design (CAD) to accelerate both the development and the accuracy of industrial systems. CAD takes many forms, often exploiting the increasing computational power of workstations to offer new tools to the end user. This has been the case of e.g. 3D visualization, which leverages the power of modern GPUs to provide realtime feedback in 3D design. In systems that involve complex physics, desktop workstations can still be insufficient however, either because of the need for High Fidelity Simulations, or because of the sheer number of small simulations that need to run. In these cases, HPC offers specific possibilities that simple workstations cannot. While originally driven mostly by research needs, these new avenues open a market for HPC in engineering applications, further driving its funding and development.
However, in times of crisis like 2020, companies have to cut down expenses. The public investment on research is staggering, as you can understand from the European Research Council letter of 22-09-2020. If the signs of recessions on the HPC market are confirmed, the future of High Fidelity Simulations is on the line. The field of High Performance Computing for the engineer will desperately need to prove its criticality in the years to come.
This feat is made harder by the fact that HPC is a complex technology that the field of engineering has little knowledge of. As an illustration, here are some questions gathered from typical of users :
- How come we cannot use 100% of this machine? In HPC, the advertised Peak performance is an upper limit, very rarely achieved in practice. So in addition to being expensive, HPC sometimes only yields a fraction of what is paid for.
- We paid a pack of 15 million CPU hours this year, but what did we really make of it? While reports often assess quantitative metrics about CPU-hour consumption, large scale data on the type of runs performed and their performance is rarely available on an HPC cluster.
In short, estimating the return on investment is very hard in HPC, making it a luxury not every company can afford. And in times of crisis, luxury goods are the first discarded.
EXCELLERAT is a European Center of Excellence that aimed to support the Excascale Computing for the engineer. By construction, it is now bound to bring a new transparency to fuel reasonable decisions on HPC. The most natural thing to do now is looking at the past to monitor what and how well/bad we used the HPC resources, and to see how to adapt…
Existing monitoring tools on an HPC cluster
About accounting
HPC clusters usually rely on batch submission software (in the present case, Slurm), which offers a command line interface for users to request compute resources, and performs allocation of these resources according to the rules defined by the sysadmin. Submission software include logs of user activity, with the primary goal of keeping track of and billing CPU-hours according to each user’s consumption. Here, Slurm is used to give an overview of how the consumption of the allocation is distributed between users.
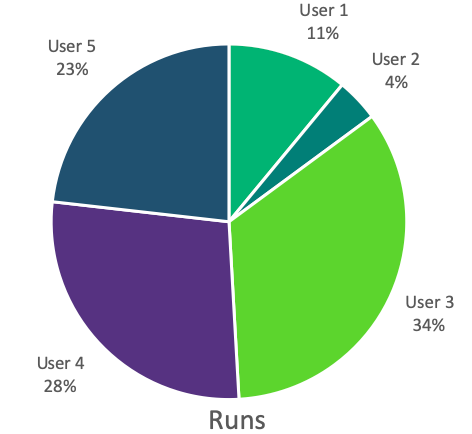
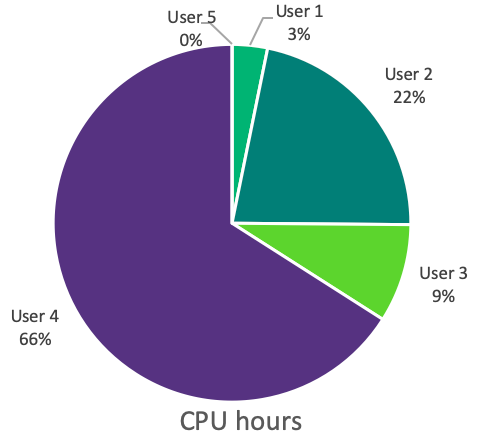 Distribution of the simulation metrics per user. User 5 is invisible on CPU hours because his jobs are small. User 4 used 66% of the total allocation with only 28% of the jobs submitted.
Distribution of the simulation metrics per user. User 5 is invisible on CPU hours because his jobs are small. User 4 used 66% of the total allocation with only 28% of the jobs submitted.
While CPU-hours are directly billed to the user, each run must be started by hand, hence the number of runs is an indication of the associated labor costs. Both of these metrics are therefore useful to assess the total simulation costs.
One should remember that a supercomputer lasts only a handful of years (3 to 7 max) and is expensive. The amortization of the equipment is calculated assuming an average load over 80%. Optimizing production is therefore critical.
The data also reveals user habits, and can inform the sysadmin to tune the job scheduling rules and improve productivity. As an example, it seems users have uneven usage patterns throughout the week.
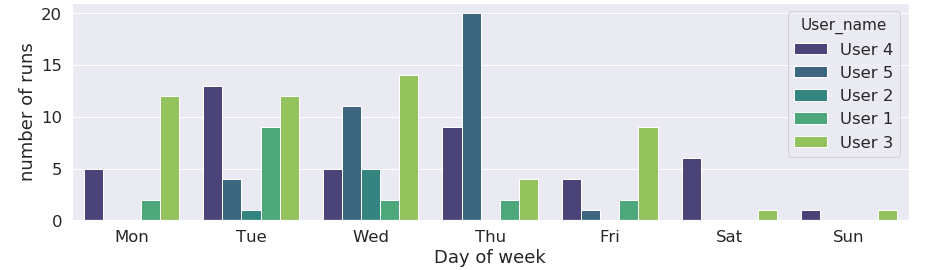 Distribution of the simulation starts per days of week. There is naturally less activity on the weekend days. This is why most clusters offer usually a *production queue* (8 to 12 hours) on weekdays, and *weekend queue* (48 to 72 hours) on weekends. A lower activity is visible on Fridays, hinting maybe the possibility of a *happy debug Friday* queue if the charge is dropping on a weekly basis.
Distribution of the simulation starts per days of week. There is naturally less activity on the weekend days. This is why most clusters offer usually a *production queue* (8 to 12 hours) on weekdays, and *weekend queue* (48 to 72 hours) on weekends. A lower activity is visible on Fridays, hinting maybe the possibility of a *happy debug Friday* queue if the charge is dropping on a weekly basis.
To get this, the administrator periodically performs a query. For example with the following unix command :
>slurm-report.sh -S 090120 -E now -T -g cfd
The job scheduler is SLURM. The command slurm-report.sh gathers information from September 1st -S 090120 to today -E now for the users group cfd -g cfd. The output looks like this:
JobID JobName Partition Group Account AllocCPUS Elapsed User CPUTimeRAW
------------ ---------- ---------- --------- ---------- ---------- ---------- --------- ----------
401637 batc prod cfd default 72 12:00:29 anonymous1 3112488
401643 lam prod cfd default 540 12:00:22 anonymous1 23339880
401805 F53NTPID prod cfd default 540 12:00:22 anonymous2 23339880
401808 F53A1NTP prod cfd default 540 12:00:22 anonymous2 23339880
401813 OFCo706 prod cfd default 540 12:00:22 anonymous2 23339880
401815 OFCo530 prod cfd default 540 03:03:16 anonymous2 5937840
401837 A_STABLE prod cfd default 540 07:54:25 anonymous6 15371100
401873 batc prod cfd default 72 00:00:00 anonymous1 0
401875 lam prod cfd default 540 00:00:00 anonymous1 0
401916 labs_lolo prod stg-elsa default 540 00:04:16 anonymous3 138240
401999 NEW_TAK prod cfd default 540 05:22:30 anonymous4 10449000
402004 Z08_URANS prod elsa default 180 07:47:19 anonymous5 5047020
(...)
There are now groups and tools focused of extracting the maximum of information from these use database. For example the UCit is developing a framework Analyse-IT based on data-science to explore the database.
The limits of accounting
The database is gathering only the information the job scheduler is aware of. The typical job profile is, at best:
- Job name
- User login and group
- Account (if needed)
- Executable Name
- Queue (Nb of cores)
- Duration requested
- Memory requested
- Start and end time
- Exit code
The executable name is is often not exploitable, because it is provided by the user, and can be /awesomepath/new_version.exe.
The exit code must also be handled with care. There is no standard of exit codes for an HPC software, so the only software related exit information is abort (MPI_ABORT for example). Other exit codes are about time-outs, parallel exception, hardware problems, all being external to the run.
The conclusion is therefore simple, there is neither engineering-related data nor software-related data under the watch of the job scheduler.
Engineering-related information.
The accounting database is not tracing engineering informations. It is like a cultivator knowing what size his fields are, how much water they needed, but without a clue about the type of crops themselves.
The missing items for a person in charge of an engineering team relying on HPC are the following:
- What are the engineering phenomenons taken into account?
- What was the size of the computation?
- What where the additional features?
Most of this figures are estimated a priori at the beginning of the year, to dimension the CPU allocation requested. However, comparisons with a posteriori figures at the end of the year are scarce.
All the data is present is the setup of a run. The challenge is to gather the setup metadata across all the runs.
A specific trait of HPC software for the engineer is asking for more : these codes are always on the bleeding edge. Compared to a commercial code, the crash probability is higher, and multiples updates a year are customary. More, software-related information would be useful.
Software-related information.
The accounting database is not tracing software informations. The persona to satisfy is now the software developer, eager to get feedback on his/her product. The open questions falls into three categories:
- What version was actually in use?
- What were the performances achieved?
- What was the job crash origin.
The software is usually providing the answers through a log file, one per run. The challenge again is to gather the log files across all the runs.
The natural solution would be to generate a new dedicated database, continuously updated like the accounting one. Unfortunately, many hurdles are waiting ahead : designing a system ; tackling permissions and confidentiality issues ; defining common definitions on performances and crashes ; and probably more unexpected challenges. This natural solution will need several years to be put in motion. We will depict here a more “brute force” approach using what is already at hand. The simulations done by engineers for design purpose are saved on archive disks -hopefully for the company-. A large amount of the relevant setups and log files are still available at the end of the year. Here follows a glimpse of a setup file and a log file for the HPC code AVBP. The typical input file of an AVBP run is stored in the run.params, a keyword-based ASCII file with several blocks depending on the complexity of the run.
$RUN-CONTROL
solver_type = ns
diffusion_scheme = FE_2delta
simulation_end_iteration = 100000
mixture_name = CH4-AIR-2S-CM2_FLAMMABLE
reactive_flow = yes
combustion_model = TF
equation_of_state = pg
LES_model = wale
(...)
$end_RUN-CONTROL
$OUTPUT-CONTROL
save_solution = yes
save_solution.iteration = 10000
save_solution.name = ./SOLUT/solut
save_solution.additional = minimum
(...)
$end_OUTPUT-CONTROL
$INPUT-CONTROL
(...)
$end_INPUT-CONTROL
$POSTPROC-CONTROL
(...)
$end_POSTPROC-CONTROL
Apparently, most of the missing information about the configuration are present. However, due to the unavoidable jargon, a translator is needed. For example, few people outside the AVBP users know that pgis the keyword for a perfect gas assumption. The content of an AVBP typical log file is presented hereafter, with many sections cropped for readability.
Number of MPI processes : 20
__ ______ _____ __ ________ ___
/\ \ / / _ \| __ \ \ \ / /____ / _ \
/ \ \ / /| |_) | |__) | \ \ / / / / | | |
/ /\ \ \/ / | _ <| ___/ \ \/ / / /| | | |
/ ____ \ / | |_) | | \ / / / | |_| |
/_/ \_\/ |____/|_| \/ /_/ (_)___/
Using branch : D7_0
Version date : Mon Jan 5 22:03:30 2015 +0100
Last commit : 9ae0dd172d8145496e8d62f8bd34f25ae2595956
Computation #1/1
AVBP version : 7.0 beta
(...)
----> Building dual graph
>> generation took 0.118s
----> Decomposition library: pmetis
>> Partitioning took 0.161s
___________________________________________________________________________________
| Boundary patches (no reordering) |
|_________________________________________________________________________________|
| Patch number Patch name Boundary condition |
| ------------ ---------- ------------------ |
| 1 CanyonBottom INLET_FILM |
(...)
| 15 PerioRight PERIODIC_AXI |
|_________________________________________________________________________________|
_______________________________________________________________
| Info on initial grid |
|_____________________________________________________________|
| number of dimensions : 3 |
| number of nodes : 34684 |
| number of cells : 177563 |
| number of cell per group : 100 |
| number of boundary nodes : 9436 |
| number of periodic nodes : 2592 |
| number of axi-periodic nodes : 0 |
| Type of axi-periodicity : 3D |
|_____________________________________________________________|
| After partitioning |
|_____________________________________________________________|
| number of nodes : 40538 |
| extra nodes due to partitioning : 5854 [+ 16.88‰] |
|_____________________________________________________________|
(...)
----> Starts the temporal loop.
Iteration # Time-step [s] Total time [s] Iter/sec [s-1]
1 0.515455426286E-06 0.515455426286E-06 0.357797003731E+01
---> Storing isosurface: isoT
50 0.517183938876E-06 0.258723148413E-04 0.184026441956E+02
100 0.510691871555E-06 0.515103318496E-04 0.241920225176E+02
150 0.517872233906E-06 0.772251848978E-04 0.239538511163E+02
200 0.523273983650E-06 0.103271506216E-03 0.241928988318E+02
(...)
27296 0.547339278850E-06 0.150002454353E-01 0.241129046630E+02
----> Solution stored in file : ./SOLUT/solut_00000007_end.h5
---> Storing cut: sliceX
---> Storing cut: cylinder
---> Storing isosurface: isoT
(...)
----> End computation.
________________________________________________________________________________________________________
_____________________________________________________________________________________________
| 20 MPI tasks Elapsed real time [s] [s.cores] [h.cores] |
|___________________________________________________________________________________________|
| AVBP : 1137.27 0.2275E+05 0.6318E+01 |
| Temporal loop : 1134.31 0.2269E+05 0.6302E+01 |
| Per iteration : 0.0416 0.8311E+00 |
| Per iteration and node : 0.1198E-05 0.2396E-04 |
| Per iteration and cell : 0.2340E-06 0.4681E-05 |
|___________________________________________________________________________________________|
----> End of AVBP session
***** Maximum memory used : 12922716 B ( 0.123241E+02 MB)
Here again, a lot of useful information for the software developer is present : version info, various performances indicators relatives to this approach, problem size. The only missing information is the reason behind a crash. There is however a way out in this case, because log files are written in chronological order.
| If the log file stops before: | the error code is: | Which means: |
|---|---|---|
Input files read | 100 | Ascii input failure |
Initial solution read. | 200 | Binary input failure |
Partitioning took. | 300 | Partitioning failure |
----> Starts the temporal loop. | 400 | Pre-treatment failure |
----> End computation. | 500 | Temporal loop failure |
----> End of AVBP session. | 600 | Wrap up failure |
| all flags reached | 000 | Success |
These error codes are code-independent. However, one can increase the granularity of the error codes by adding code-dependent custom codes. For example in AVBP, a thermodynamic equilibrium problem is raised by the error message Error in temperature.F which can return a specific code (e.g. 530) to keep track of this particular outcome.
Gathering the data.
In this brute force approach, a script is run on the filesystem, while complying to the Unix permissions. This data-mining step can take some time. Here is a rough description of the actions we used for this illustration:
- First search for the log files , and discard duplicates with a checksum comparison.
- Find the corresponding setup file.
- Parse the log file with all the regular expression arsenal and compute the error code.
- Parse the setup file , again with the regular expression arsenal.
- Keep that of the creation date and the login of the creator
- File this data into a database.
The final database is then filled with both pre-run information (the setup, version time, and username) and post-run information (error codes, performances, completion).
One should keep in mind two biases already present in the newly created database. First this database will not take into account runs erased during cleanup operations. It cannot be considered exhaustive. Second, all runs are equally represented (with an equal interest). In reality only one out of ten runs, at best, is actually contributing to a motivated engineering conclusion. Some runs are only taken to check to versions of the same code give similar results. The added value of a specific run, compared to another, is subjective.
We however have now a quite interesting database to investigate…
Identifying the content of the harvest
We can invite here machine learning to help us handle this heap of data. Principal Component Analysis (PCA) is a well-known technique to reduce dimensions of data. From a lot of components, we can bring down our runs to a 2, 3, or 4 component descriptions.
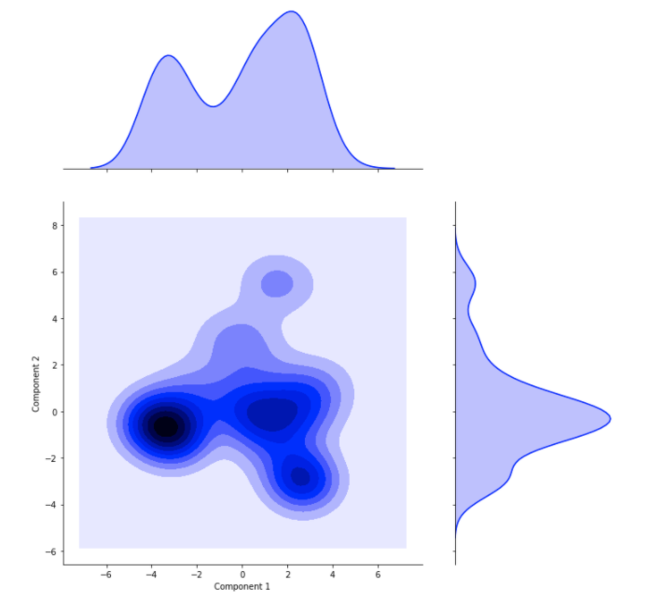
The simulations inputs parameters are reduced to two components able to reproduce the variety of the simulations. This cross plot shows the scattering or simulations along this two components. Two major clusters are visible, followed by one, maybe two minor clusters.
Once PCA is done, we do have a simpler representation of the variability on the database, but no clue about what are these clusters. We can gather groups of similar runs thanks to clustering. We see in the following 2-components scatter plot that runs have been automatically separated into three groups that have close parameters and can be described to belong to the same family of runs. This way runs can be sorted without human supervision and bias by model, or dimension or any interesting parameter the model makes arise.
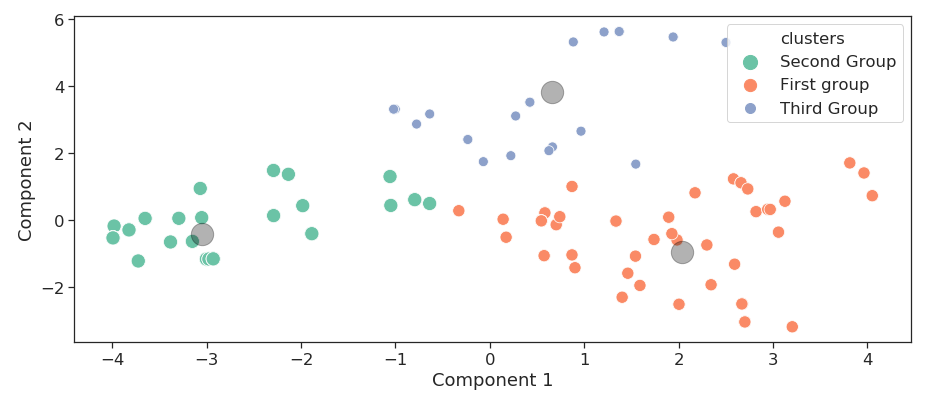
Three families of runs are gathered with a clustering analysis. Groups are sorted in population order: the first group include the biggest number of runs, followed by the second and the third.
Runs can be gathered together, according to their convection scheme, artificial viscosity or LES model, the version of the code used and the mixture name.
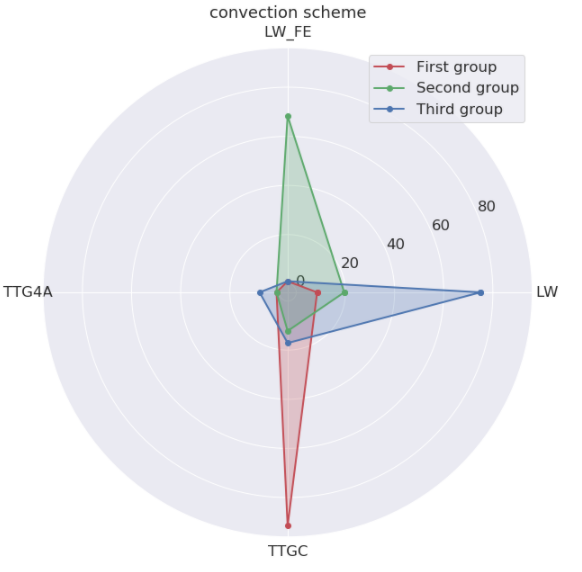
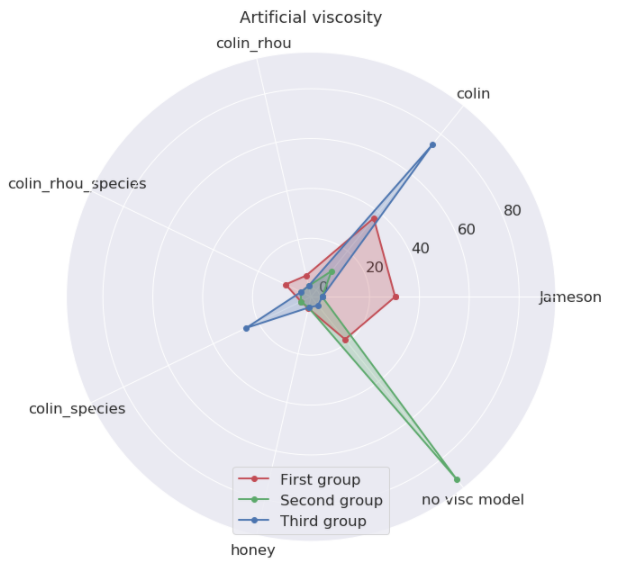
The *convection scheme* is a critical precision element. LW is a second order, robust scheme when precision is not needed. TTGC is a third order, low-dissipative and tricky scheme, which is 2.5 time more expensive. The *artificial viscosity* is the strategy used to damp the *scheme* imperfections.
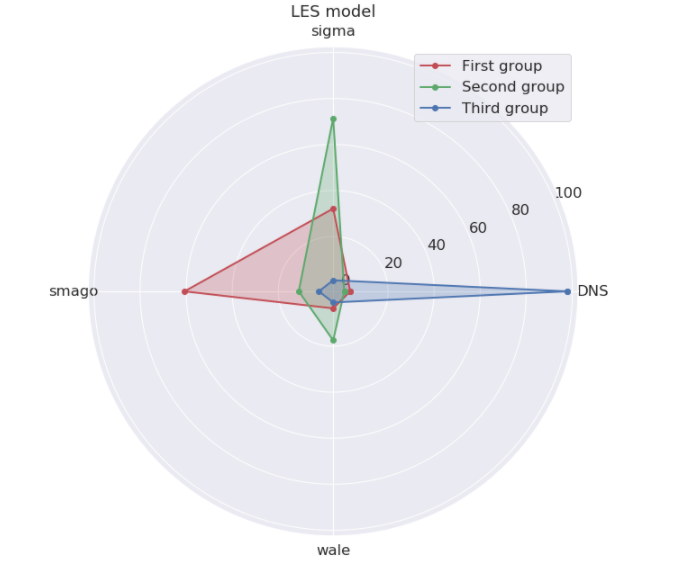
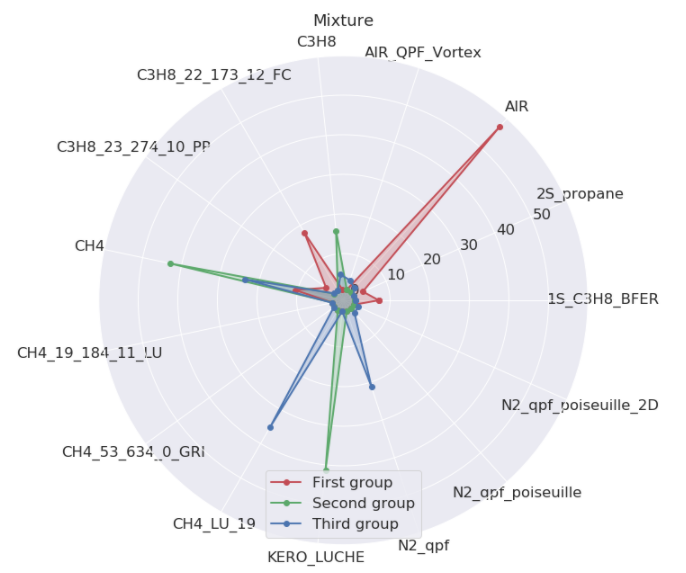
The *LES model* is the way the turbulence is computed at scales smaller than the grid. Like the *scheme*, some options are harder to stabilize (sigma). Note that `DNS` means in this particular case that no model was used. The *mixture name* is the gas composition. AVBP is a reactive solver. `AIR` is your everyday oxygen-nitrogen cocktail, `KERO`, `C3H8` and `CH4` the usual fuels Kerosene and Methane. Other mixtures are for test purpose (`*_qpf_*`) or higher precision fuel kinetics `(fuel)-_(n_specs)_(n_reac)*`.
The actual content of the harvest
This batch of simulation can be divided into three families:
- The largest family is about non-reactive (AIR) configurations done with high order schemes (TTGC)
- The second family is the reactive runs with classic fuels (KERO, CH4, C3H8) with normal finite elements schemes(LW–FE). Surprisingly for the expert, there is often no artificial viscosity, but a complex LES model (Sigma)
- The third family is done with a normal scheme (LW) and no LES model, therefore laminar flow with no need of precision on the convection. This last group is harder to sketch. A decomposition in four group might have helped.
This is giving now a clearer picture on what has been actually simulated.
Version acceptation
HPC users can exhibit a lot of inertia in their version upgrades. Who can blame them: in this continuous bleeding edge optimization, chances are highs that the newer version will bring new bugs. However the software team cannot let them roam free, the older the version is, the harder the support will be. Here we will track the adoption rate of new versions among users.
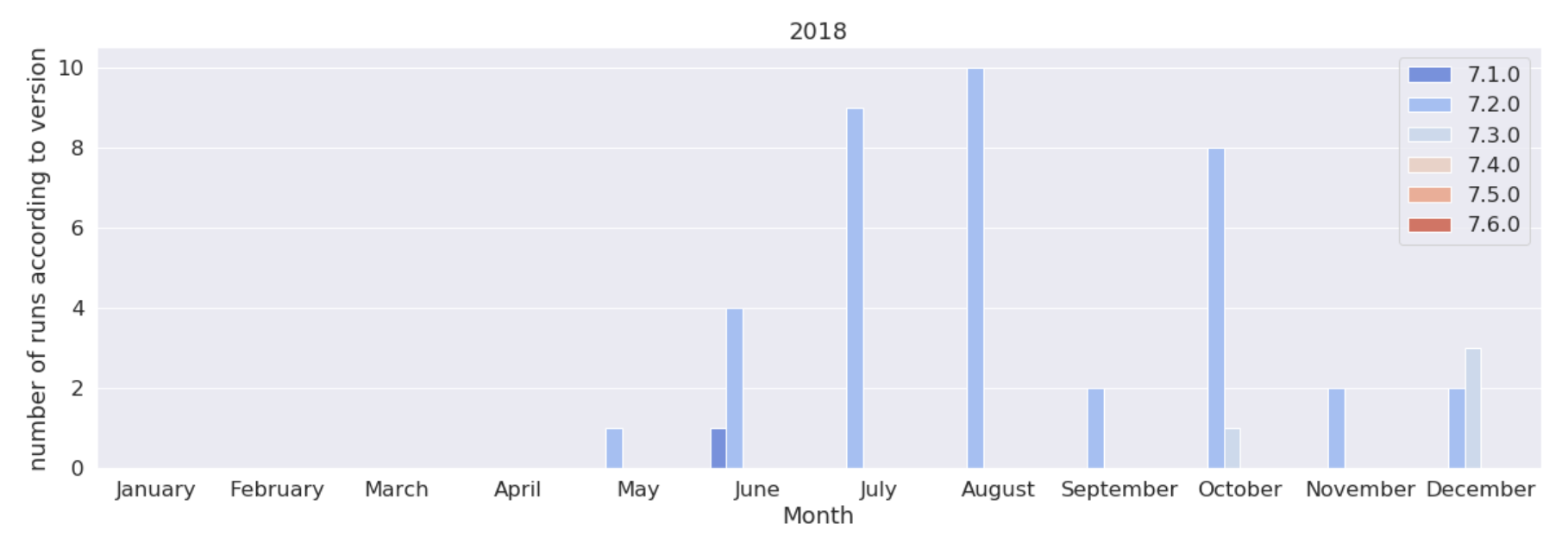
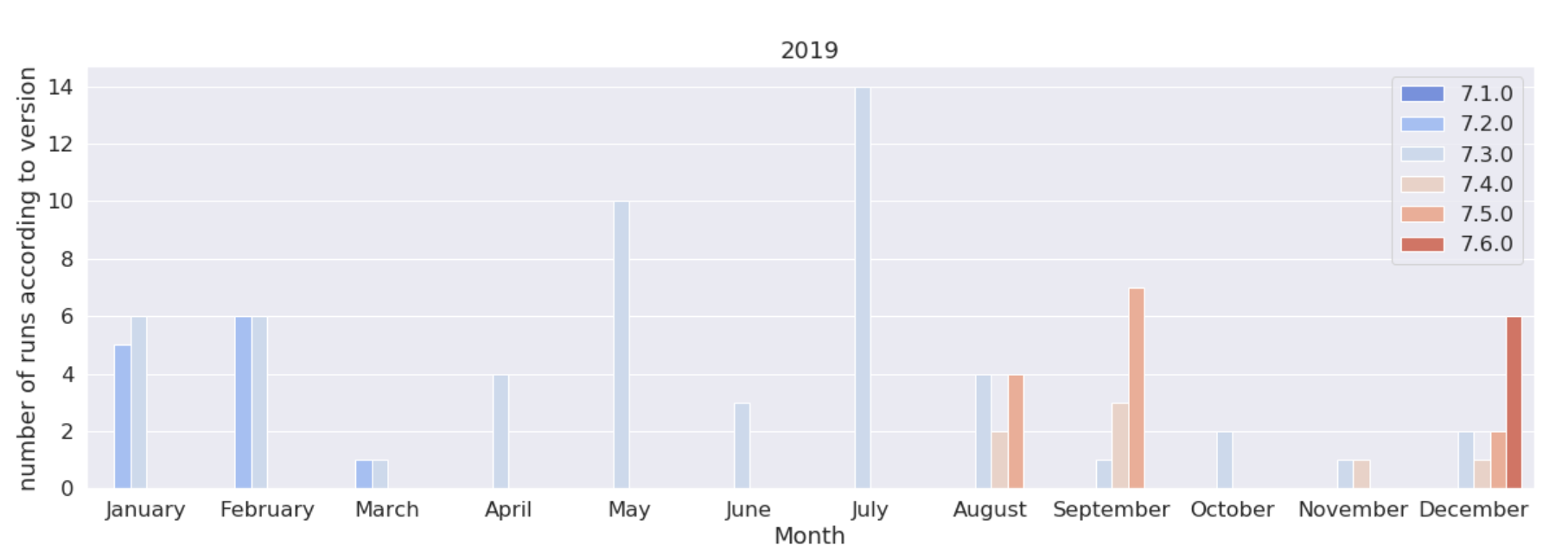
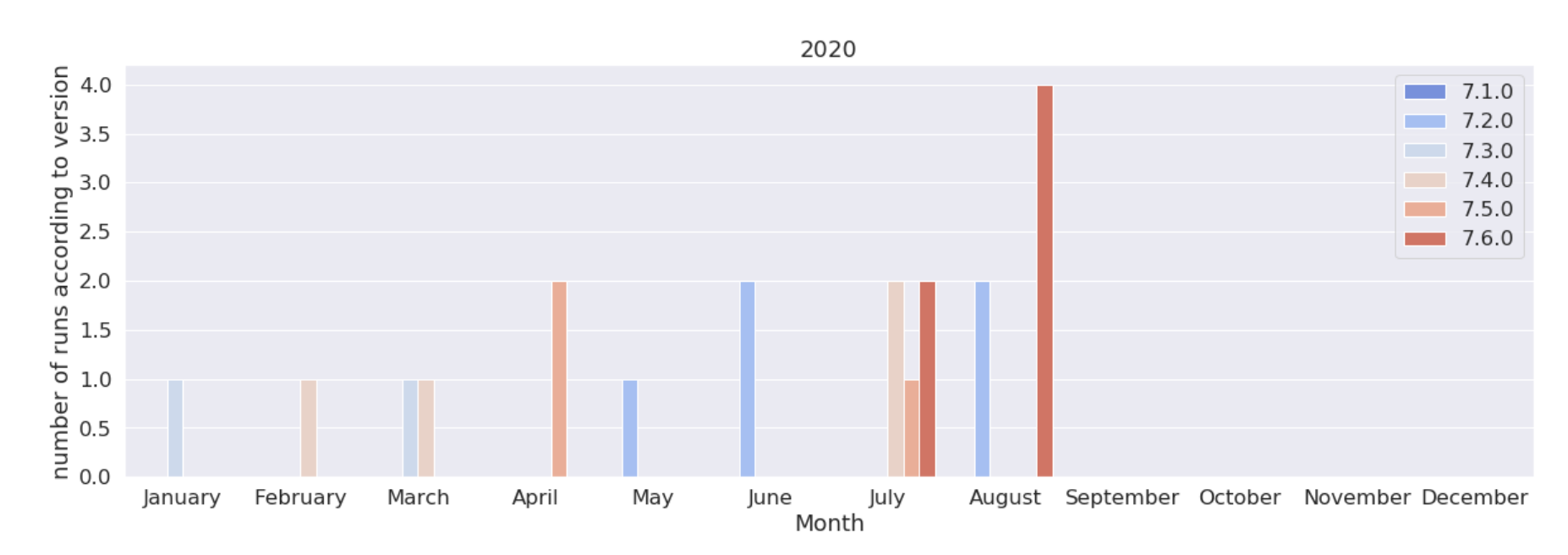
These are the version of the code used in 2018, 2019, 2020. We see here that the 7.3, released in Sept. 2018, was used a lot more that its sequels, until the 7.6 released in March. 2020. Note that 7.6 even got an “early bird” peak in Dec. 2019 due to a pre-release test campaign
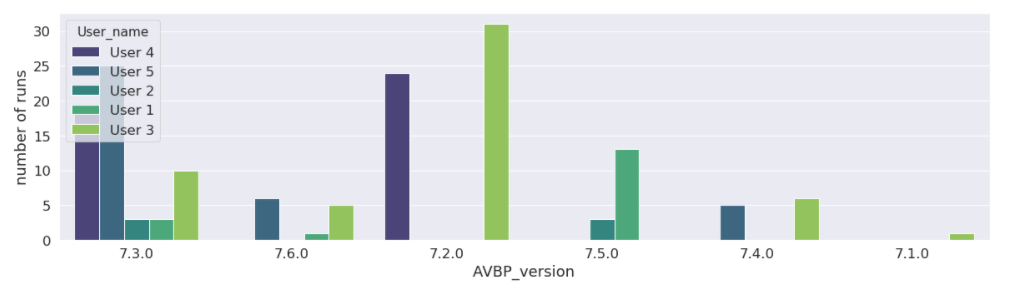 This shows the “popularity” of each versions among users, in decreasing order. Apparently user 2 and 4 never moved to the 7.6 version. User 4 stayed limited to the 7.3 version, while using 66% of the CPU hours.
This shows the “popularity” of each versions among users, in decreasing order. Apparently user 2 and 4 never moved to the 7.6 version. User 4 stayed limited to the 7.3 version, while using 66% of the CPU hours.
Quantify the problems
Software support is the elephant in the room : it takes most of the time of software team, but is never mentioned, you probably would jinx it. We were talking about reducing the stress on the support team, maybe we can help them to target the weakest points of the code?
This pie chart highlights the percentage of runs that went through and those which crashed, due to different errors. An error code of ‘0’ indicates a run that went through. Any other error code means it crashed.
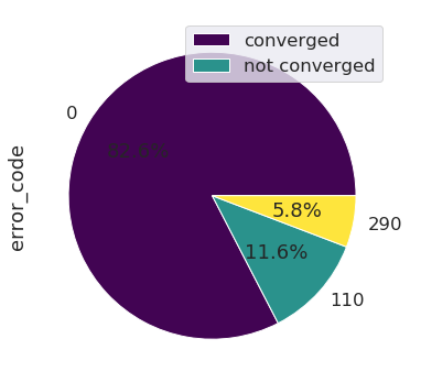
This shows that on this database, very few runs actually crashed during the time loop. The main crash causes were found at the setup, either when filling the input file (110) of the binary databases for the boundaries (290).
Here we see that almost 12% of the runs crash due to an error code of ‘110’ which means bad filling of the input file. The CPU hours are not waisted, but the end-user hours are, and this build resentment. Various idea could pop : – maybe the parser is too strict? – or the documentation could be improved? – Could it be that some dialogs are giving the wrong mental model? Here the support team should not give in the temptation to guess. With the new database, one can focus on the runs crashed and get new insights, either by manual browsing, or a new data-science analysis if there are too many.
 Some users -an undisclosed but substantial number- run over the time limit, loosing the last stride of unsaved simulation in the process. The reason : downsizing the run could stop it before end of the allocated time, which is seen less efficient.
Some users -an undisclosed but substantial number- run over the time limit, loosing the last stride of unsaved simulation in the process. The reason : downsizing the run could stop it before end of the allocated time, which is seen less efficient.
Actual versus expected performance
If you are an HPC expert, some critical data linked to HPC itself will be of high interest.
We will start will the most basic HPC pledge : my code is faster on a higher number of processors. On a priori benchmarks with controlled test case, the figures are nice and clean. What about an a posteriori survey on the harvest itself?
We compute here the efficiency. This metric is used to compare machine performances with this code and numerical scheme. It is expressed in µs/iteration/degree of freedom. It is the time needed to advance one iteration (a computation step), divided by the number of degrees of freedom (the size of the mesh). Efficiency should not compared between two different codes, since the iteration is a code-specific concept, and the d.o.f. are also difficult to convert.
In one way or another, it must linearly decrease with the number of cores to satisfy the pledge.
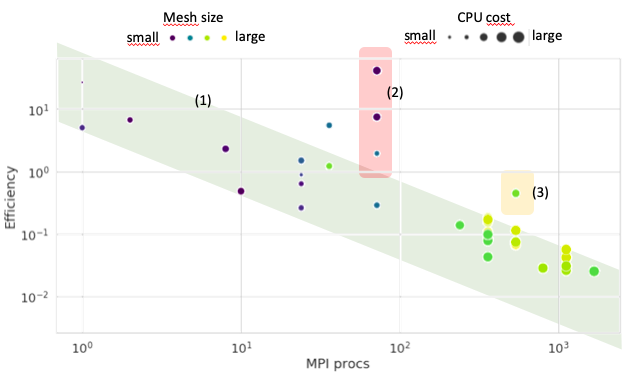 Most of the jobs are indeed showing an efficiency decreasing linearly with the number of processes. In this linear zone (1), bigger meshes efficiency is less good, drifting away from the lower bound of the linear zone, but these simulation often use more equations and models. Some CPU consuming tasks show terrible performances (2) and should be investigated. A large simulation is also underperforming (3).
Most of the jobs are indeed showing an efficiency decreasing linearly with the number of processes. In this linear zone (1), bigger meshes efficiency is less good, drifting away from the lower bound of the linear zone, but these simulation often use more equations and models. Some CPU consuming tasks show terrible performances (2) and should be investigated. A large simulation is also underperforming (3).
We can see the linear trend with the number of MPI processes. This overall trend is right. Unfortunately, there are terrible outliers : 2 orders of magnitude slower on the same code and same machine cannot not be taken lightly. A special investigation should focus on this.
If we dig further in the code-dependent figures, the cache of AVBP can be optimized with the ncell_group parameter. As this is configuration dependent and features dependent, the process of finding the right tuning has always been heuristic. Here we look at a heat-map of the ncell_group parameter versus MPI processors to go even further and check if the association of both parameters is right.
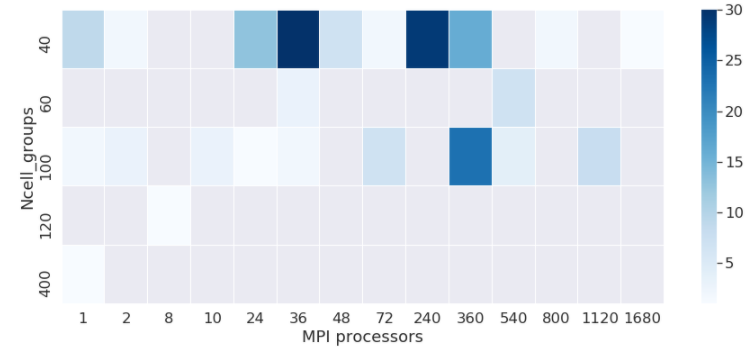 Survey on what `ncell_group` is tested by the user to improve their simulations on the partitions. The fact that only 5 values are found is the proof very few people take the time to optimize the cache with respect to their simulation
Survey on what `ncell_group` is tested by the user to improve their simulations on the partitions. The fact that only 5 values are found is the proof very few people take the time to optimize the cache with respect to their simulation
At Excellerat, we anticipate that HPC simulations will reach a tipping point by the end of 2020. When companies dimension their demands for 2021 and forecast their needs for the 2021-2025 period, it will be in the context of a global economic crisis. The addition of these decisions will shape the future of the HPC market. That is why, in our opinion, the ability to give precise insights on what and how well HPC design was done in the last years is the best way to make reasonable and sustainable decisions.
Luckily, there is already a lot of data sleeping on our filesystems. This article showed one way to do it using a crude crawler and data-science off-the-shelf techniques, but there are probably many more ideas already in motion on this matter. The biases of this approach must not be overlooked, as some elements were not assessed here. The two most prominent are our new database is non-exhaustive by construction and we treated simulations equals, disregarding their specific added value. Both are important flaws with the current brute-force way, and should be improved in the future.
A word of warning. When applying these approaches, one should keep the Mc Namara Fallacy in mind, detailed by D. Yankelovich:
The first step is to measure whatever can be easily measured. This is OK as far as it goes. The second step is to disregard that which can’t be easily measured or to give it an arbitrary quantitative value. This is artificial and misleading. The third step is to presume that what can’t be measured easily really isn’t important. This is blindness. The fourth step is to say that what can’t be easily measured really doesn’t exist. This is suicide. — Daniel Yankelovich, “Corporate Priorities: A continuing study of the new demands on business” (1972).
Until today, there was no strong incentive for a quantitative monitoring of the HPC industrial production in terms of phenomenon simulated, crashes encountered, or bad user habits. Those were not quantifiable and usually disregarded. If we add this kind of monitoring to the HPC toolbox more largely, we could also open a production hell where the monitoring metrics will become new additional constraints. By the means of the Goodhart’s law, the production quality could worsen even under this new monitoring. We would have quit one fallacy just to stumble into an other one. If by any means such initiative become a new layer of additional work, this will be a sad backfire. The mindset of the work presented here is to reduce the work, the stress and the waste of both human and hardware resources.
The authors wish to thank M. Nicolas Monnier, head of CERFACS Computer Support Group for his cooperation and discussions, Corentin Lapeyre, data-science expert, who created the first “all-queries MongoDb crawler”, and Tamon Nakano, Computer science and data-science engineer who followed-up and created the crawler used to build the database behind these figures. (Many thanks in advance to the multiple proof-readers from the EXCELLERAT initiative, of course)