Success Story: Accelerating engineering codes using reconfigurable architectures
Success story # Highlights:
- Keywords:
- FPGA testbed
- Memory-bound code
- Dataflow
- Industry sector: code development
- Key codes used: Nekbone, Nek5000, Alya

Organisation involved:
Edinburgh Parallel Computing Centre at the University of Edinburgh has been founded in 1990 and has for objective to accelerate the effective exploitation of novel computing throughout industry, academia and commerce. With over 110 technical staff and managing ARCHER2, the UK national supercomputer, and numerous other systems EPCC is the UK’s leading supercomputing centre. With over 30 years of experience in HPC and computational simulation, many of EPCC’s staff are involved in projects such as EXCELLERAT exploring techniques to optimise and improve codes on modern and next generation supercomputers.
scientific Challenge:
EXCELLERAT is all about making engineering codes ready for Exascale, which involves focusing on both the specific use-cases contributed by CoE partners and providing services to a much wider range of application owners. However, many such engineering and scientific codes are often not entirely compute bound, but instead suffer from other bottlenecks including how quickly data can be loaded from main memory. As a community some great advances have been made, but arguable many of these are low hanging fruits, and if we are to fully exploit future Exascale systems then we need to have the techniques and hardware available that can address the wider set of properties that constrain application performance and scaling.
Such challenges are further compounded by the fact that the processing technologies we associate with HPC, namely CPUs and GPUs, hide the implementation of how a user’s code is actually run at the electronics level (the microarchitecture) from the programmer’s view of their code. Therefore, considering Exascale, an important question is whether there are benefits to unifying these views, and if so how.
In EXCELLERAT we have been looking at reconfigurable architectures, and specifically Field Programmable Gate Arrays (FPGAs), which enable the use to configure a chip to electronically represent an application. This means that the FPGA can execute the code directly at the electronics level without numerous layers of indirection present in CPUs or GPUs. Furthermore, the high levels of concurrency provided by these technologies means that parts of the FPGA can be computing whilst other parts are streaming in and/or reorganising data. This is compounded by the very high bandwidth connections between the chip and outside world (typically an order of magnitude greater than CPUs and GPUs) and therefore overall, we think that they can be very effective for codes which are memory or microarchitecture bound.
However, traditionally FPGAs were in the domain of the hardware designer rather than the software developer, due to their highly specialist and esoteric nature. This meant that, whilst the HPC community have seen significant potential in the technology for a long time, it has not been until recently that they have become a more realistic proposition.
Solution:
In the past few years there have been significant advances at both the FPGA hardware level (far more capable hardware able to perform more advanced computation) and the software ecosystems. The latter is crucially important, as vendors such as Xilinx have done a fantastic job of making their toolchains more acceptable to software developers, and as we have seen with numerous technologies in HPC such an acceptance is critically important if a technology is to be successful.
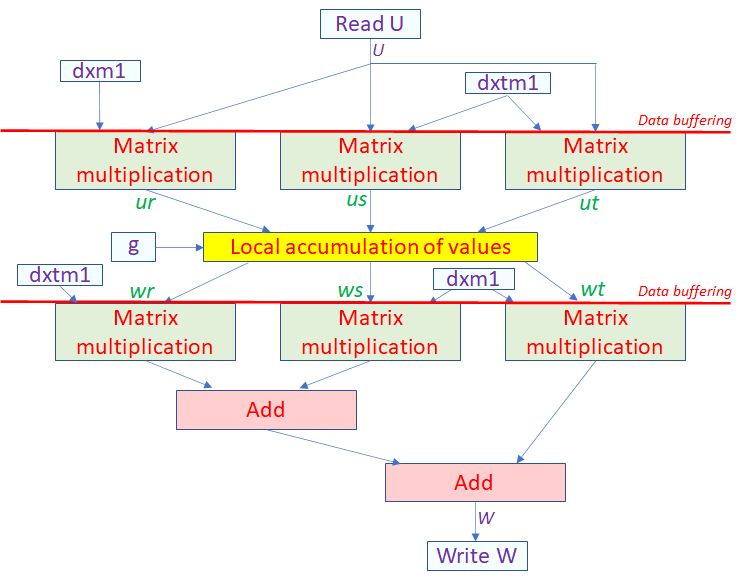
Therefore, based on all these advances we believe it really is time to look again at FPGAs for HPC, especially within the context of the memory bound challenges discussed above. As part of EXCELLERAT we have been exploring the role of reconfigurable architectures for several of our CoE use-case codes. Tackling those which we believe could demonstrate significant benefits on the FPGA, we have been exploring the most appropriate algorithmic techniques to deliver such benefits. Nekbone, a proxy app for Nek5000, is a prime example here, where the main AX kernel is bound by memory accesses (we suffer from a parallel efficiency of around 0.5 when scaling from 1 to 24 cores on a Xeon Platinum Cascade Lake CPU with 100% memory bandwidth occupied) and therefore we redesigned it in a dataflow style. The diagram below illustrates our dataflow design for this kernel where the boxes are functions running concurrently and connected by streams of data. The idea is that different parts of the FPGA can be running concurrently on different elements of data, some computing whilst others are fetching and reordering data ready for later stages. Therefore, by keeping all parts continually busy, streaming data onto the next when it is ready, potentially we can address the bottlenecks on the CPU.
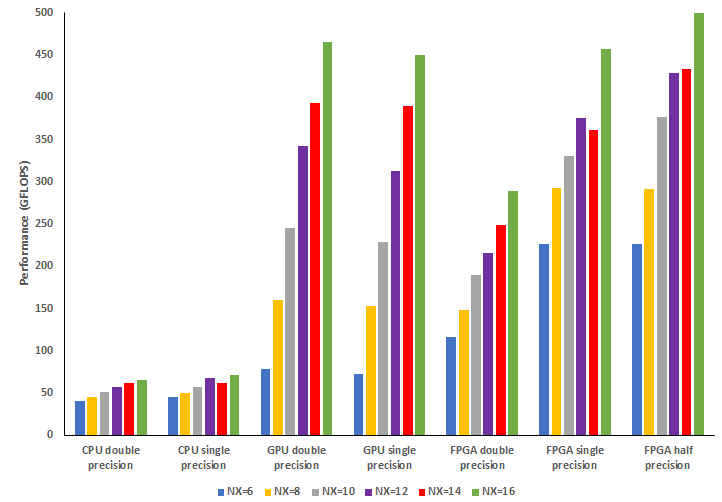
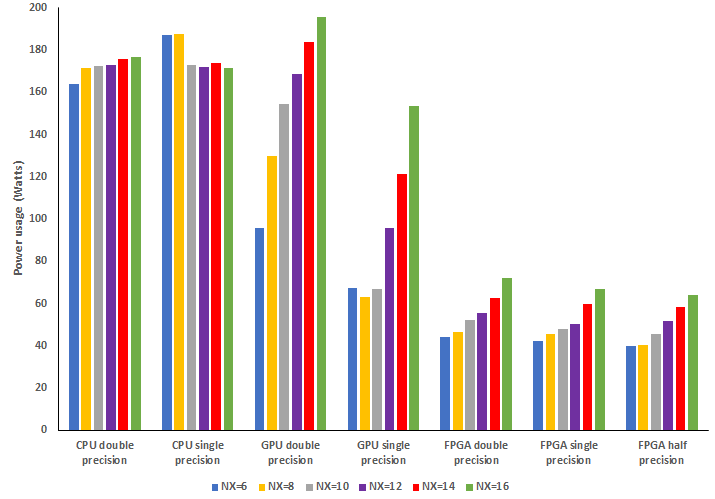
The proof of the pudding is in the eating, and the first diagram below illustrates performance for the AX kernel on the 24-core Intel Xeon Platinum Cascade Lake CPU, a NVIDIA V100 GPU, and Xilinx Alveo U280 FPGA. Depending upon the exact configuration being used, we demonstrate about five to six times the performance of the CPU for double precision on the FPGA, which then increases as we move to single and half precision on the FPGA. This is a really good result for the Alveo FPGA, but the GPU is far more competitive with some experiments performing better on the FPGA, and others on the GPU. One also must consider power draw as this is often a significant limitation imposed on the size of a supercomputer, and the second graph illustrates that the FPGA draws significantly less power compared to the CPU and GPUs. Both these measures are really important, as they help explore how such a technology can provide benefits for HPC in future Exascale systems.
impact of this solution:
In addition to the CoE use-cases themselves, exploring the most appropriate dataflow techniques and which will benefit by moving to this new class of accelerator, the work undertaken in EXCELLERAT has formed the foundation of us looking to contribute to FPGAs becoming more widespread in HPC.
In order to achieve the latter, we need to make the technology available to application developers with as low a barrier to entry as possible. The EXCALIBUR programme in the UK is looking to take scientific codes to the Exascale, and as part of this they have a Hardware and Enabling Software (H&ES) component which is funding a number of innovative testbed systems. EPCC led a joint bid with UCL, Warwick and Xilinx to install an FPGA testbed in Edinburgh, and the experiences developed and results demonstrated in EXCELLERAT were crucial to strengthening our claims around why FPGAs could be a very interesting and important technology for HPC at exascale.
This testbed will be used by scientific and engineering code developers from the UK and wider world. The way in which we have planned to set up and provision the testbed has been driven by lessons learnt in EXCELLERAT, and whilst we already have a number of users lined up, the intention is that many future activities will be able to sign up and experiment with the technology.
Therefore, the activities undertaken in EXCELLERAT are having two major impacts, firstly at the technology level with the techniques and codes themselves, and secondly more widely for the HPC community to help encourage other developers to port their codes over to FPGAs and demonstrate its potential for HPC.
Benefits for further research:
- Optimisation of performance for appropriate codes
- Significantly reduced power draw, for instance with the experiments on Nekbone described here we are around twice as energy efficient (GFLOPs per Watt) as the GPU and ten times that of the CPU.
- We have developed numerous dataflow algorithmic techniques – there can be many thousands times difference in performance between the first version and the optimised code on the FPGA.
Unique Value:
- FGPAs typically have an order of magnitude more bandwidth than other technologies
- FPGAs enable a tailor-made effect and support the effectiveness of the chip to the execution of the simulation code
Products/services:
- A consultancy on “How to port Simulation code to the HPC architecture”
EPCC would like to thank Xilinx for their donation of an Alveo U280 which has been used for this work and porting other codes of interest in the CoE to FPGAs.
If you have any questions related to this success story, please register on our Service Portal and send a request on the “my projects” page.