



CERFACS is a theoretical and applied research centre, specialised in modelling and numerical simulation. Through its facilities and expertise in High Performance Computing (HPC), CERFACS deals with major scientific and technical research problems of public and industrial interest.
GENCI (Grand Equipement National du Calcul Intensif) is the French High-Performance Computing (HPC) National Agency in charge of promoting and acquiring HPC, Artificial Intelligence (AI) capabilities, and massive data storage resources.
Cellule de Veille technologique GENCI (CVT) is an interest group focused on technology watch in High Performance Computing (HPC) pulling together French public research, CEA, INRIA among Others. It offers first time access to novel architectures and access to technical support towards preparing the codes for the near future of HPC.
AVBP is a parallel Computational Fluid Dynamics (CFD) code that solves the three-dimensional compressible Navier-Stokes on unstructured and hybrid grids. Its main area of application is the modelling of unsteady reacting flows in combustor configurations and turbomachines. The prediction of unsteady turbulent flows is based on the Large Eddy Simulation (LES) approach that has emerged as a prospective technique for problems associated with time dependent phenomena and coherent eddy structures.
Some physical processes like soot formation are so CPU intensive and non deterministic that their predictive modelling is out of reach today, limiting our insights to ad hoc correlations, and preliminary assumptions. Moving these runs to Exascale level will allow simulation longer by orders of magnitudes, achieving the compulsory statistical convergence required for a design tool.
The complexity at the code level to unlock node level and system level performance is challenging and requires code porting, optimisation and algorithm refactoring on various architectures in the way to enable Exascale performance.
In order to prepare the AVBP code to architectures that were not available at the start of the EXCELLERAT project, CERFACS teamed up with the CVT from GENCI, Arm, AMD and the EPI project to port, benchmark and (when possible) optimise the AVBP code for Arm and AMD architectures. This collaboration ensures an early access to these new architectures and prime information to prepare our codes for the wide spread availability of systems equipped with these processors. The AVBP developers got access to the IRENE AMD system of PRACE at TGCC with support from AMD and Atos, which allowed to characterise the application on this architecture and create a predictive model on how the different features of the processor (frequency, bandwidth) could affect the performance of the code. They were also able to port the code to flavors of Arm processors singling out compiler dependency and identify performance bottlenecks to be investigated before large systems become available in Europe.
The AVBP code was ported and optimised for the TGCC/GENCI/PRACE system Joliot-CURIE ROME with excellent strong and weak scaling performance up to 128,000 cores and 32,000 cores respectively. These optimisations impacted directly four PRACE projects on this same system on the following call for proposals.
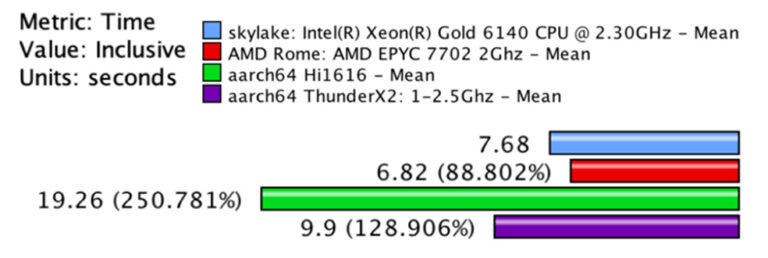
Beside AMD processors, the EPI project and GENCI’s CVT as well as EPCC (EXCELLERAT’s partner) provided access to Arm based clusters respectively based on Marvell ThunderX2 (Inti Prototype hosted and operated by CEA) and Hi1616 (early silicon from Huawei) architectures. This access provided important feedback on code portability using the Arm and gcc compilers, single processor and strong scaling performance up to 3072 cores.
Results from this collaboration have been included on the Arm community blog [1]. A white paper on this collaboration is underway with GENCI and CORIA CNRS.
AVBP offers the possibility to use unstructured grids than can be automatically adapted to the flow at runtime allowing for automatic tracking of the zones of interest. Additionally mesh quality criteria in AMR can compensate for any defects on the original grid that might lead to numerical issues.
References:
If you have any questions related to this success story, please register on our Service Portal and send a request on the “my projects” page.