Success Story: Enabling Nek5000 on GPU systems
Success story # Highlights:
- Keywords:
- GPU
- NVIDIA
- AMD
- OpenACC
- OpenMP
- SEM
- Nek5000
- Industry sector: Automotive, Aerospace
- Key codes used: Nek5000

Organisations & Codes Involved:

The Swedish e-Science Research Centre (SeRC) is a national e-science initiative, funded by the Swedish government Strategic Research Area Initiative, dedicated to provide e-infrastructure support and to improve important e-science software on future HPC platforms. The largest part of this support is provided by giving researchers access to the national computational experts and infrastructure and to promote collaboration between scientific experts and computational experts.
Nek5000 is an open-source code for the simulation of incompressible flows. Nek5000 is widely used in a broad range of applications, including the study of thermal hydraulics in nuclear reactor cores, the modelling of ocean currents, and the simulation of combustion in mechanical engines.
Topic of collaboration:
Collaboration between EXCELLERAT and SeRC is concentrated on improving the performance of the Nek5000 programme and getting Nek5000 ready to run on future hardware. There is a common interest in developing this CFD solver as it is the reference code for both EXCELLERAT and SESSI, which is one of the SeRC’s research communities. This scientific code allows to perform high-fidelity simulations of relatively complex and industrially relevant flows. It shows as well very good parallel scaling properties making it a good candidate for Exascale computing.
In particular, it was necessary to port and optimise Nek5000 on GPU systems, specifically systems using hardware provided by NVIDIA and AMD. As part of the collaboration, it was necessary to examine the best practices in porting the code to the different software environments provided by AMD and NVIDIA and look at ways to re-use and standardise the work required due to the different hardware and software.
Results of collaboration:
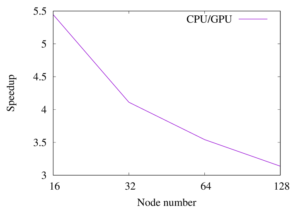
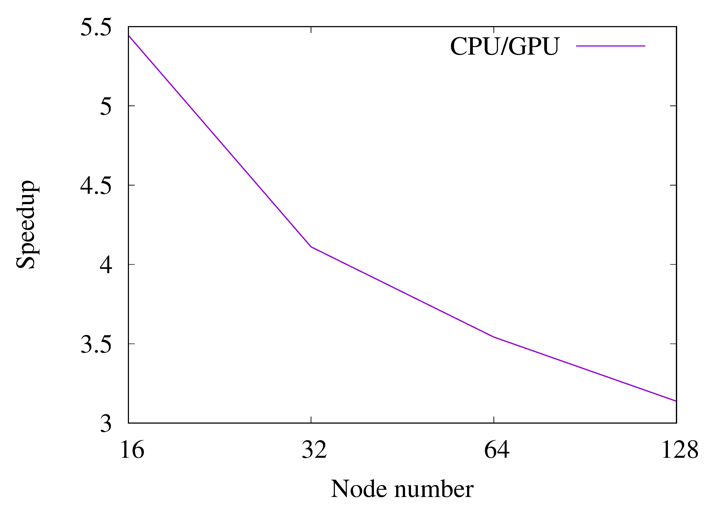
The first achievement of the collaboration between EXCELLERAT and SeRC was the extension of the CPU version of Nek5000 to run on NVIDIA GPUs using OpenACC directives. The results showing the performance of the two versions are given in Fig. 1.
After profiling the OpenACC version it was found that the directive approach was creating some inefficient small kernels. After merging some kernels by rewriting them in CUDA, a significant reduction of their total runtime was achieved, for example for calculations running on A100 machines replacing 6 OpenACC kernels in a loop with a single CUDA Fortran call reduced the runtime from 800 µs to 200 µs.
Also, as part of the profiling work, several routines were found to have significant bank conflicts when certain input was used. When these were removed the duration of the affected kernels improved by around 20%.
In addition to the OpenACC version, an OpenMP version using GPU offload has been created to enable Nek5000 to run on AMD GPUs. This is necessary due to the poor support for OpenACC provided by the AMD toolchain. The OpenMP version has currently a similar performance as the OpenACC version.
What did we manage to do together that we could not have done separately?
Before the start of the collaboration, it was only possible to run Nek5000 on CPU systems. The very good parallel scaling of the CPU version allowed the problem to scale to a large number of CPU cores, but it is clear that to run on Exascale machines it would be necessary to update Nek5000 so that it could run on GPU nodes.
In addition, the OpenACC support using the AMD toolchain is poor. Similarly, the support for OpenMP with GPU offload with the NVIDIA toolchain is also poor, so it is required to create both an OpenACC version and a version using OpenMP with GPU offload, to ensure that Nek5000 can run efficiently on both AMD and NVIDIA systems.
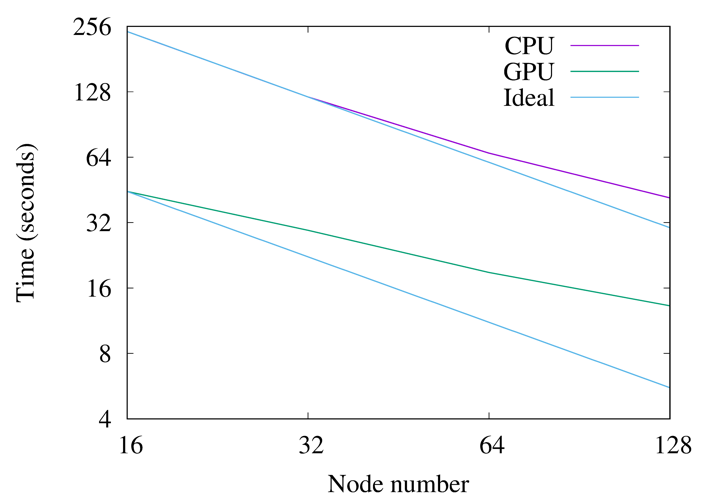
As a result of the collaboration, we created GPU implementations using both OpenACC and OpenMP of Nek5000, ensuring that Nek5000 is ready for use on Exascale architecture. The results of a pipe simulation experiment performed on the JUWELS Booster at Jülich Supercomputing Centre (JSC), comparing OpenACC/CUDA version and CPU version (1 node has a 48 core AMD EPYC and 4 A100 GPUs) is given in Fig. 2.
{kind=link}
{kind=link}
If you have any questions related to this success story, please register on our Service Portal and send a request on the “my projects” page.