Success Story: Enabling sustainable GPU acceleration on a Fortran legacy code
Success story # Highlights:
- Keywords:
- CFD
- combustion simulation
- parallel performance
- GPU computing
- OpenACC
- Industry sector: Aerospace, Automotive
- Key codes used: AVBP
Organisations & Codes Involved:
CERFACS is a theoretical and applied research centre, specialised in modelling and numerical simulation. Through its facilities and expertise in High Performance Computing (HPC), CERFACS deals with major scientific and technical research problems of public and industrial interest.

AVBP is a parallel Computational Fluid Dynamics (CFD) code that solves the three-dimensional compressible Navier-Stokes on unstructured and hybrid grids. Its main area of application is the modelling of unsteady reacting flows in combustor configurations and turbomachines. The prediction of unsteady turbulent flows is based on the Large Eddy Simulation (LES) approach that has emerged as a prospective technique for problems associated with time dependent phenomena and coherent eddy structures.
Technical Challenge:
AVBP is a cutting-edge software when it comes to distributed memory CPUs (efficiently scaling up to 200.000 of cores). However, many of the most powerful HPC systems heavily rely on GPU accelerators, and this trend will likely accelerate with the upcoming Exascale systems. Extending AVBP to support GPU architectures in addition to the current CPU implementation seems mandatory to efficiently use computing resources in the Exascale era.
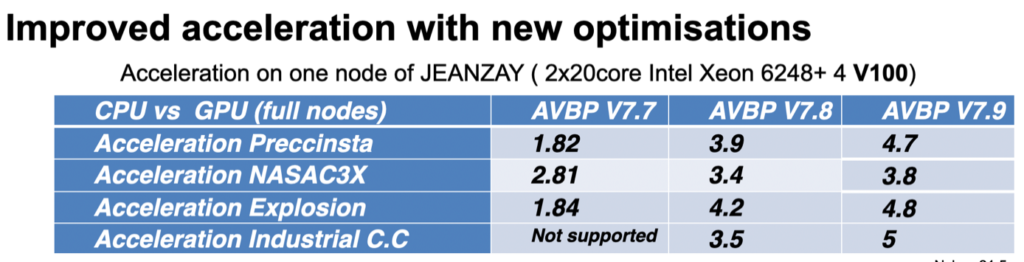

Solution:
AVBP is both a legacy Fortran code and a very active research project; this implies that we have a very large and rapidly evolving code base. Most of our developers are undertaking PhDs in CFD, and have limited expertise in HPC per se. Porting this code to GPU cannot occur at the expense of its accessibility and maintainability, thus we chose to use OpenACC which provides both the ability to offload computations to GPUs through the addition of simple pragmas while reducing the impact in the source code. Only minor parts of the code require a full rewrite to run efficiently on GPU and keep CPU compatibility. Most of the difficulty came from the management of data exchanges between the GPU memory and its CPU host (mainly due to the legacy memory structure of AVBP which does not take into consideration potential needs to manage the data locality) and the limitations of OpenACC for deep-copy.
Scientific impact of this solution:
The porting of AVBP has been challenging as the code base is large and there are no specific performance bottlenecks that concentrate the computational load; instead, there are many small routines that deal with various aspects of the simulation. In a first approach we tried to offload high-level routines but this proved to be unsuccessful due to the complexity of the underlying call stacks and data management.
Therefore we went the opposite route of fine-grain incremental porting, identifying computationally intensive loops and porting them one at a time along with the data movement operations needed. Although very cumbersome, this approach allowed us to port all the relevant operations on the GPU, advancing and validating the results step-by-step. Having successfully achieved the port is a first result in itself, as it shows that a large legacy code can effectively be extended to GPUs with a minor impact on the code.
The GPU port has been officially integrated into AVBP since release 7.7 and improved upon for each new release. Researchers using it can thus now benefit from GPU partitions on every relevant HPC system (with NVIDIA cards). The switch is worthwhile since a single GPU ( using nVidia V100) can carry the computational load equivalent to two hundred CPU cores (here Intel Cascade Lake). Further optimisations are still to come which will leverage more performance.
This work was supported and performed in collaboration with IDRIS, the Cellule de Veille Technologique GENCI and HPE.
Benefits for further research:
- Release of a GPU ready CFD code
- Leveraged performance of GPU nodes on HPC systems superior to pure CPU nodes
- Maintained accessibility of the code to non-HPC developers
Products/services:
- Best practices for GPU porting for legacy code
- Best practices for CFD using GPU hardware
If you have any questions related to this success story, please register on our Service Portal and send a request on the “my projects” page.