
As part of the EXCELLERAT project, SSC is developing a secure data exchange and transfer platform to facilitate the use of High-Performance Computing (HPC) in industry and to make data transfer more efficient. Furthermore, many companies do not have an academic and research context for High-Performance Computing. Any industrial solution available on the market offers high-performance computing without a connection to research. On the other hand, most scientific institutes focus almost exclusively on the research approach without any interaction with industry. The unique selling point of the platform is that we can also offer industry access to HPC via academic institutions.
Nowadays, organizations and smaller industrial partners face various challenges in dealing with HPC computations, HPC in general, or even access to HPC resources. In many cases, the computations are complex and the potential users do not have the expertise to fully exploit HPC technologies without support. The developed data delivery platform will be able to simplify or even eliminate these hurdles. The platform will allow users to easily access both the Hawk and Vulcan HLRS computing systems from any authorized device and perform their simulations remotely.
In collaboration with several industrial pilot partners, the platform prototype is undergoing various tests of its suitability. All user requirements and feedback are subsequently being incorporated into further development and optimization in order to provide the greatest possible added value for future users from different sectors.
1. Goals
- Increase availability of HPC resources for industry
- Provide a secure data transfer platform for small and medium enterprises (SMEs) and simplify the HPC barrier to entry for industry
- 2.2 Target groups
- Companies: Simulation engineers of all disciplines (e.g. CFD).
- Researchers at universities
- High-performance computing centers
2. Functions of the prototype
- Administration of users and high-performance computers
- Creation and management of individual computational projects
- Ability to upload input files, run simulations, download results
- Connection to supercomputers: Hawk and Vulcan from HLRS.
3. Added value for customers
- Reduction of HPC complexity through a web frontend
- Computations can be started from any location with a secure connection
- Time and cost savings through a high degree of automation that optimizes the process chain
- Reduction of sources for manual errors
4. Added value for HLRS
- Shorter training periods for users and reduced support efforts
- Higher HPC customer loyalty due to a less complex HPC environment
- Vision: shared use in other EU projects (e.g. FF4EurosHPC).
1. Platform structure
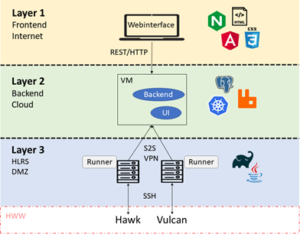
The data exchange platform is divided into several independent modules and layers:
- Layer 1: Presentation Layer
- Layer 2: Application Logic and Metadata
- Layer 3: HPC client component with runners
- Layer 4: HPC machines in the high-performance computing center
The different layers build on each other and should avoid two-way dependencies. Thus, a higher layer is always dependent on all layers below it, but not the other way around.
1.1 Layer 1
The presentation layer is accessible from the Internet and performs two tasks in the platform. First, it implements the actual user interface, which is presented to the user in graphical form. Second, it takes over the tasks of dialog control such as events triggered by the user through mouse clicks. In this layer, the JavaScript web framework Angular from Google is used as the software component for the user interface. Layer 1 is provided in Layer 2 as a container. As soon as new container versions are available, they are automatically installed with the next platform release.
In order to protect the web frontend from attacks from the Internet, the communication protocol HTTPS is used and the IP requests can be limited by “rate limits” within the Kubernetes cluster in Layer 2. By specifying how often a client can call the Web API, the risk of a DDoS or other attack is reduced.
The user accesses the platform interface from the Internet via the URL “excellerat.ssc-services.de”. Port forwarding is set up from port 80 to 443 so that an encrypted connection (TLS) is always established between the web server and the browser. The communication with the user interface and the backend component takes place in layer 2 via port 443. This HTTPS connection is always just an incoming connection initiated by the client. An e-mail-password combination is used for authentication for the user interface. Currently, there are no password guidelines, but for production deployments it would be conceivable that special characters, lowercase and uppercase letters and numbers could be mandatory. In addition, two-factor authentication (e.g., a time-based one-time password) is planned.
Within this layer there is also a GitLab instance. This will be used by SSC to manage all repositories and the data that defines the infrastructure. This makes it possible to quickly bring new releases into the production environment (“continuous delivery”). The GitLab server is hosted by SSC, but is also accessible from the Internet.
All subsequent layers are located in different networks and separated by firewalls at the High-Performance Computing Center Stuttgart.
1.2 Layer 2
In the second layer, all components (including the user interface from Layer 1) run in Docker containers in a Kubernetes cluster (K8s for short). The second layer contains all the processing mechanisms of the application: including the algorithms, rules, and structures necessary to describe the elements and functions of the platform.
It is ensured at all times that the end user has no control over the orchestration and cannot run their own images.
One of the overall goals of running a server or cluster is to minimize costs. This requires maximum utilization of resources. The goal is to eliminate any useless additional effort. The approach used for this is container technology in the form of Docker containers. Due to its lightweight structure and resource-minimizing approach, this is a basis for achieving the above-mentioned goals. The following figure reflects the structure of a container-based virtualization with Docker.

As can be seen in the figure, the infrastructure and the host operating system (OS) form the basis. This is followed, in contrast to a VM, not by a hypervisor, but by a so-called container engine. In this case, Docker, which accesses functionalities of the host OS.
Kubernetes is an open-source container orchestration platform that simplifies container handling and data management across the cluster by automating the deployment and scaling of containerized applications.
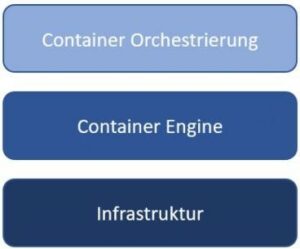
The following figure is a simplified representation of how orchestration fits into the container landscape. For this purpose, certain components are abstracted and summarized. As the figure shows, the basis of container orchestration is the infrastructure. Building on top of the infrastructure is the container engine, such as Docker. Above that is the container orchestration.
Four different containers run in the cluster: database (PostgresSQL), message broker (RabbitMQ), user interface (Apache HTTPD image + custom web interface) and the backend (Java image + custom data dispatcher). Within the platform, the latest stable versions, based on the version tags, are always installed in a timely manner. The data dispatcher is the brain of the platform and is responsible for intelligently managing and dispatching the data. All containers are dynamically scalable and have no fixed resource limits. All cluster traffic is controlled via the service mesh Istio and it is specified which traffic may go in and where it must go.
The cluster only connects to the outside (internet) to get updates from the appropriate Docker registries. The images for Postgres, RabbitMQ and Apache are in the official Docker Hub (“https://hub.docker.com/”). Our own images (web interface and data dispatcher) are currently located in the Google Cloud in a separate Docker Registry. A separate Docker Registry within the Kubernetes cluster is planned.
The Docker Registry forms a source for Docker images, in which Docker images are stored and can be reused. In addition, the registry can be used both privately and publicly. When used publicly, all Docker users can use the saved image and use it in a Docker file. The figure below illustrates the aforementioned behavior.
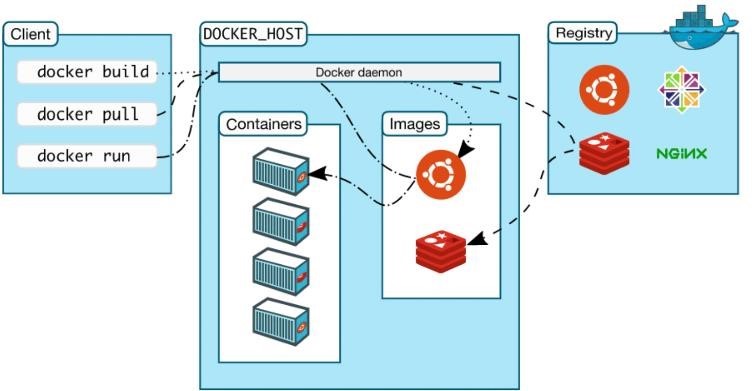
Docker images form the basis of a container. The image is an executable package and contains all the necessary dependencies to be able to launch an application in a container. Images are not modifiable, as they form a kind of snapshot of the system at a particular point in time. This means that the same content is always reproduced when the images are reused. The result of this behavior is a reproducible image that cannot be changed. Only the official images are used in the platform. These are signed and all data has a known origin. This ensures that foreign containers with malicious code are not used by the platform. The entire backend is managed automatically in the background and the user has no access to or influence on this. To improve the security of layer 2, the hardening and RBAC mechanisms are used. The most stable version (“latest stable”) of Docker is always used. Moreover, only trusted users are allowed to have control over the Docker daemon by ensuring that only trusted users are members of the Docker group. Furthermore, all containers are run as non-root users and only minimal, trusted base images that do not contain unnecessary software packages are used, which keeps the potential attack surface low.
Within the Kubernetes cluster, role-based access control (RBAC) is also used to regulate access to compute or network resources. RBAC authorization uses the “rbac.authorization.k8s.io” API group to make authorization decisions and configure policies dynamically through the Kubernetes API.
Once a user uploads data through the platform, the backend initiates a connection to Postgres and RabbitMQ and the HPC client component of the VM from Layer 3 simultaneously initiates an inbound connection to RabbitMQ. However, the data flow works in both directions.
The LDAP server is currently not yet available.
1.3 Layer 3
In the third layer, a VM with the client component of the platform is located in a demilitarized zone (DMZ). All communication from the DMZ to the K8s cluster takes place via RabbitMQ. The message broker communicates via port 5672, which is secured with a username and password. The data uploaded by the user is placed in a queue by the data dispatcher at RabbitMQ. These messages are monitored, read, and executed by the HPC Runners. The HPC Runners are Java applications that run as Systemd processes on the VM. Systemd processes are background programs (daemons) for Linux systems that serve as init processes, the first processes to start, monitor, and terminate other processes.
Through these processes the VM knows whether it needs to transfer data to Hawk or Vulcan. There is a standalone runner for both HPC machines.
The authentication mechanism used here for the runner processes is based on SSH access. Here, the public SSC enterprise IP address is whitelisted at HLRS. Otherwise, the VM is only accessible to internal HLRS staff via SSH access. The runner logs in with the stored user data (encrypted, private key).
SSC services can connect directly to the VM via an SSH connection (port 22). However, access to the public Vodafone source IP (178.15.58.20) has been restricted for this purpose.
1.4 Layer 4
The last layer contains the two HPC data systems that are currently available in HLRS. The login nodes of Hawk and Vulcan are located in the same production network (141.58.155.0/24) and are not further divided into subnets.
Only the existing tools (e.g., workspaces, batch system) are accessed in this layer. SSC does not run any other software components on the nodes itself.
As soon as the user uploads data via the platform and specifies where it should be computed, the system checks whether there is already a workspace on the corresponding HPC machine. If there is no workspace yet, it is created first and then the corresponding folder is mounted on Hawk or Vulcan via SSHFS (port 22). SSHFS (Secure SHell FileSystem) is a network file system that allows data storage from other machines to be securely mounted to your own file system via SSH over an encrypted network connection.
Once the data driven simulations are ready and the user downloads their results via the platform, RabbitMQ notifies the appropriate runner that data is needed from the workspace. These are also retrieved via SSHFS. However, the files to be transferred are not transferred in one piece, but in 1 MB blocks due to the data reduction technique used.
The advantage of SSHFS over other techniques such as SFTP, SCP or RSYNC is the ability to also transfer incomplete files to specific positions in a file to write.
The uploaded data as well as the database entries are handled within containers, but eventually they have to be stored on a block device. For the end user, it is important here that the data can also be deprovisioned again, for example when an account is logged off. A distinction must be made here between metadata and user data. The metadata (e.g. user information, file name, …) is stored in the K8s database. K8s uses a “storage operator”, which in turn uses the disk storage of the corresponding VM. However, the user data is not cached, but passes directly through. It is only kept in RAM for a short time.
2.2 Technology Stack
The programming language is Java. Google’s JavaScript web framework Angular is used for the user interface. Micronaut is used as a JVM-based framework for building modular applications and microservices together with Gradle as a build tool. The service mesh platform Istio is used to control the communication of the individual containers within the Kubernetes cluster. This allows control over how the different components of the application share data with each other. The database used is the relational database Postgres. The versioning system GitLab is used as the code repository, where the integrated CI/CD pipelines are also used to test and implement the workflows. The corresponding components and all Docker images are built here. Using Continuous Delivery, changes can be pushed automatically to the Kubernetes production environment. The package manager HELM is used to manage and deploy Kubernetes applications. RabbitMQ is used as a messaging broker for communication or message distribution.
2.3 Data Reduction Technique
The goal of data reduction is essentially to avoid data redundancy on a storage system. With the help of this storage technique, only as much information as necessary is to be written to a non-volatile storage medium in order to be able to reconstruct a file without loss. The more duplicates that are removed, the smaller the amount of data that needs to be stored or transferred. To do this, the files are first broken down into small data blocks (chunks) and given unique checksums, known as hash values. A tracking database containing all checksums serves as the central control instance.
The data management technique is based, among other things, on the InterPlanetary File System protocol, a peer-to-peer method of storing and sharing hypermedia in a distributed system. Here, the cryptographic hash function SHA256 and Base58 encoding are used. Within the hash trees, the SHA256 checksums are combined, which in turn are combined into a new hash. Therefore, the probability of a possible SHA256 hash collision is very low.
Thus, the identification of redundant chunks is based on the assumption that data blocks with identical hash values contain identical information. In order to filter out redundant chunks, the deduplication algorithm requires newly determined hash values to be matched against the tracking database only. If the deduplication algorithm finds identical checksums, the redundant chunks are replaced by a pointer that points to the location of the identical data block. Such a pointer takes up much less space than the data block itself. The more chunks in a file that can be replaced by placeholders, the less storage space the file requires.
The data reduction takes place in the background of the platform. As soon as a user uploads a file via the platform, a hash tree is calculated from the entire file, which is broken down into 1 MB blocks (chunks). Using this hash tree, the data dispatcher can determine which parts have been uploaded before and which have not. As soon as the data is no longer available in the system, the complete hash tree is deleted.
1.1 Update Procedure
Especially in critical infrastructures and for applications that can endanger privacy, it is important to ensure the security of software. In order to ensure the unique origin of updated software, the authenticity of updates must also be guaranteed. The latest versions of all components and frameworks are always used in the platform. To ensure authenticity, only the official and signed Docker images from the manufacturers are used. These updates can be transferred and installed on the corresponding target machines within a few minutes via Continuous Integration/Continuous Delivery (CI/CD) pipelines in GitLab. Furthermore, only Long-Term Support (LTS) distributions are used for all servers.
1.2 Availability
The platform is based on a container-based infrastructure managed by the Kubernetes orchestration platform. This can ensure fast response in case of failure and easy scalability under high load. Due to the capabilities that Kubernetes offers in distributed environments, there is high availability for all services. It is guaranteed at all times that the infrastructure is available to authorized users. However, if there are any issues with the K8s cluster, the platform may be unavailable for a short period of time.
1.3 Data Integrity
The term data integrity refers to the correctness, completeness and consistency of data. This means the stored database information remains permanently correct, complete and trustworthy, no matter how often it is accessed. To ensure that data is not corrupted during a transmission, hash trees are used in the platform to provide a digital signature, for the purpose of authenticating a message. A hash tree is a tree of hash values of data blocks, for example from a file. They enable efficient and secure verification of data structure contents. Before a user uploads a file via the platform, a hash tree is computed and the chunk hash is subsequently validated on the target machine.
1.4 Authenticity
The communication partners are exclusively the users of the platform and the corresponding operators of the HPC machines. The identity of the users is ensured via a synchronous login mechanism consisting of an email and a password. The initial start password is set individually by the user after the first login. Additional two-factor authentication using a hardware device (e.g. YubiKey) or software (e.g. Google Authenticator) is planned.
To connect the platform to the machine user, the user must enter their SSH credentials on the corresponding cluster once. Communication between the machine and the workspace takes place exclusively via HTTPS. The login credentials are not stored on the platform, they only need to be entered once to connect to the mainframe and the respective HPC resource on behalf of the user. An SSH key pair is generated and the public key part is entered into the application user. The private key is stored encrypted in our database.
The access is only needed for a short time, but it establishes persistent access to the user’s account on the platform. The user can disconnect from the corresponding HLRS machine at any time, which also deletes both parts of the key. Moreover, the user can also manually log in to the cluster and manually remove the authorized key there.
Furthermore, it is impossible for the platform administrators to view the login data for HLRS. This is only used for one-time authentication on the mainframe and then discarded.
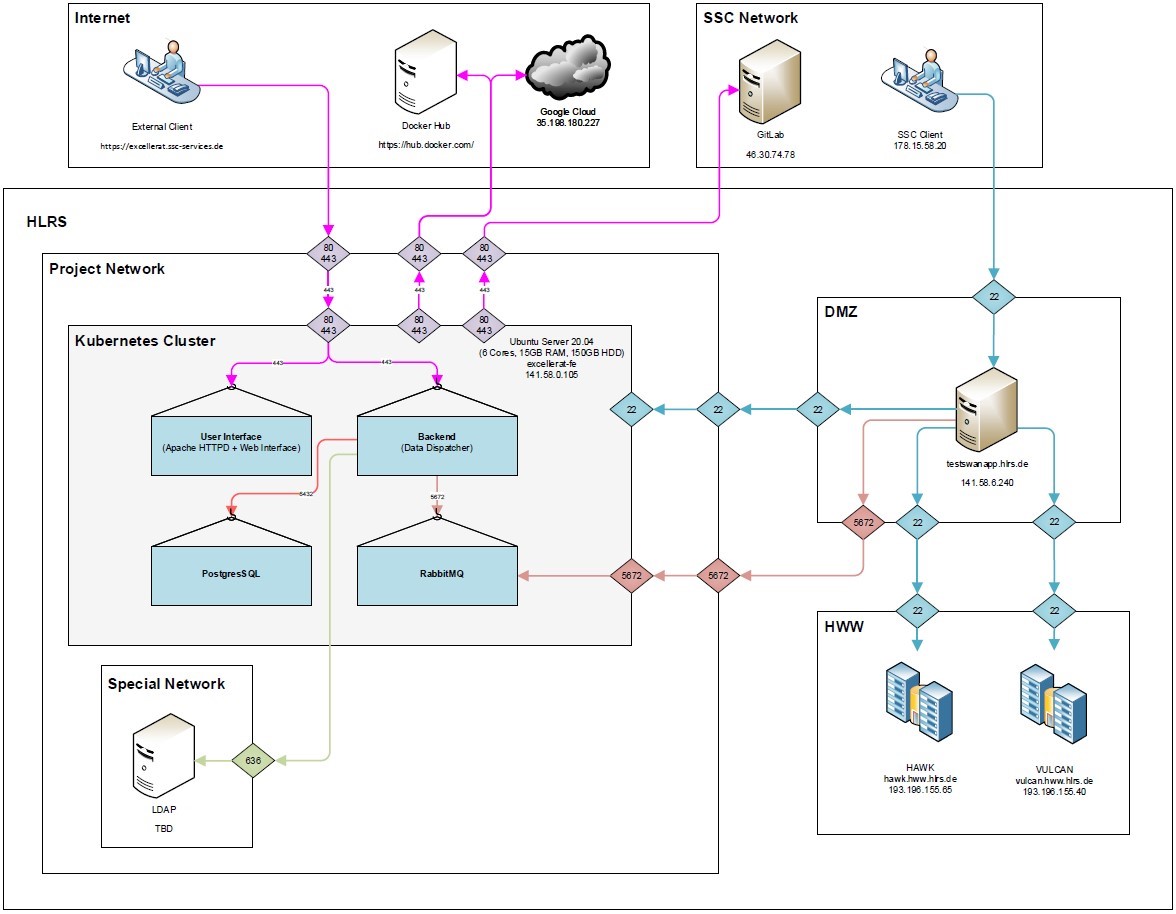
In the following network plan, all relationships between the different components are graphically shown. This shows how the devices communicate with each other and how information flows through the network. All components have been explained in more detail in the previous chapters.
The research and implementation to date confirms the assumption that high performance collaboration is a serious business case. The current product has proven that data collaboration does not require complex expertise. This thesis is further supported by the already collaborating pilot partners and their feedback.
Architecturally, the application will be optimized so that it can be used both in clouds and on premise. Furthermore, an automatic user registration is planned. For advanced users, we will offer an editor directly in the portal so that changes can be made quickly and easily. A two-factor authentication will secure the product portfolio in terms of security. Further ideas are a graphical representation of the workflow as well as copying or versioning.
As a second main component, data management will be implemented in the product. Here the ideas range from simple tasks, such as cleaning or managing directories, to the use of machine learning and artificial intelligence. This could be used to generate workspaces based on empirical values or characteristics or to realize suggestions for calculations or optimized data transfer.
This white paper was written in German by Jens Gerle, Joachim Grimm, and Christopher Röhl from SSC-Services GmbH. It was translated by Sally Kiebdaj, HLRS.