The EXCELLERAT Best Practice Guide is an outcome of EXCELLERAT, the European Centre of Excellence for Engineering Applications. The centre of excellence (CoE) was a project established in December 2018 and funded by the Horizon 2020 framework programme in order to establish the foundation of a central European knowledge and competence hub for all stakeholders in the usage and exploitation of high-performance computing (HPC) and high-performance data analytics (HPDA) in engineering.
Having worked together throughout the 42 months of the initial funding phase, we are presenting this Best Practice Guide of ways and approaches to execute engineering applications on state of the art HPC-systems in preparation for the exascale era.
As the best practice guide is a comprehensive document structured by the EXCELLERAT approach to HPC-usage in engineering problems, we provide an introduction and overview of its structure to guide the interested reader to relevant information within the comprehensive document.
All tasks and actions of EXCELLERAT are driven by the requirements of using HPC for executing engineering applications. Therefore, the Best Practice Guide is also organized by the typical usage path of scientific computing applications in engineering research and development, as shown in Figure 1.
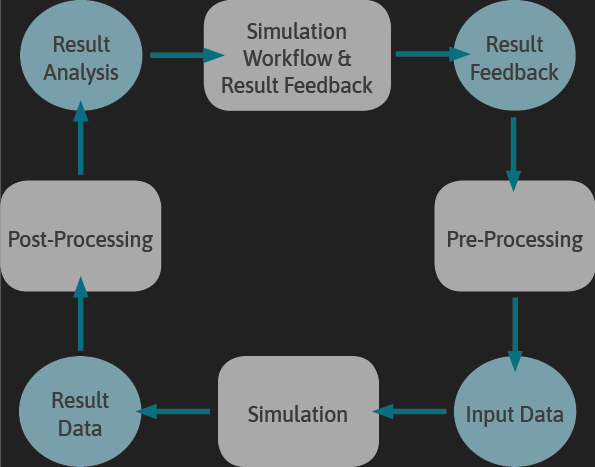
Starting with Pre-Processing, including all tasks relevant to input data generation and preparation, we next move to the so called “Simulation” step that represents the classical “execute a given code or software framework on a large remote computing resource based on prepared input data and produce output data”. From there we proceed to the Post-Processing step. Nowadays due to the ever-growing amounts of output data, it includes not only visualization but also all forms of data analytics that enable the knowledge extraction and generation based on the simulation step’s output data. The fourth step that has a dedicated section within the Best Practice Guide is the “Simulation Workflow and Results Feedback” step. In the simplest case, the post-processed result data is transferred to the user’s site. However in the more complex cases, all kinds of methodologies and techniques that require automatic result feedback like optimization- or uncertainty-quantification methods are used. To cover topics like Performance Engineering and Co-Design that are relevant for all the steps in the workflow, especially if they are to be executed in an automated fashion, the last section of the Best Practice Guide contains all “Workflow Overarching Activities”.
Since addressing all areas of interest related to the steps of the engineering workflow is not possible within a limited timeframe and limited resources, the most essential and relevant tasks requiring the most attention for the successful and efficient use of HPC in engineering were identified based on various use cases during the first phase of EXCELLERAT. These use-cases in turn were selected based on their relevance (especially for targeting exascale applications), impact, and the degree to which they represent HPC-usage in engineering. Since we believe that the idea of EXCELLERAT as the central access point in Europe for knowledge, competence, and know-how dissemination related to all facets of HPC-usage in the field of engineering is worth carrying forward, we as the EXCELLERAT consortium will keep on working on further use-cases and the derivation of best practices to ease the usage and uptake of HPC as a tool for faster, more efficient, and sustainable research and development in engineering.
Given the diversifying landscape of hardware options suitable for all parts of the engineering workflow and the rise of specialised system technologies for data analytics, we especially foresee that system-engineering and co-design as well as workflow handling in all its facets will be relevant sources for the extension and comprehensive completion of the EXCELLERAT best practice guide in the coming years.
As depicted in Figure 1, the engineering workflow is composed of four steps. The steps are derived from the classical simulation task in engineering in which a given physical problem is described via a set of partial differential equations whose solution is made universally computable by the application of a discretization scheme like e.g. the Finite Volume Method.
In order to be able to execute the implementation of the discretized model, the pre-processing step in which the input data of the model are prepared is the first task. After the execution, i.e. the simulation step, the produced result data have to be analysed in the Post-Processing step. In the Result Feedback step, conclusions are drawn from the analyses of the results data. These are used to modify the input data and thus trigger the next design cycle.
If one takes a closer look at the usage of HPC in engineering, all arising tasks can be assigned to one of these four steps. This remains true even in applications of pure HPDA in which the simulation step is not necessarily an actual simulation model but rather the execution of analysis software.
Even though this is true for almost all tasks from the application user’s perspective, it becomes more complicated once the application developer’s perspective (or even system vendor’s or system integrator’s perspective) is taken. This is especially true when performance engineering or co-design tasks are considered with the target of finding a system architecture on which an automated design cycle including all steps of the engineering workflow should be executed efficiently.
To also cover these cases and especially the performance engineering aspects which are relevant for all steps of the engineering workflow, a fifth section was introduced called Workflow Overarching Activities in addition to the four sections, “Pre-processing”, “Simulation”, “Post-processing”, and “Simulation Workflow and Results Feedback”.
In the engineering workflow, the pre-processing step collects not only all tasks concerned with model preparation like domain discretizations i.e. meshing, physics specification and boundary application etc. but also all tasks connected with data transfer from the user’s site to the HPC centres. Two major areas requiring considerable improvements were identified during the course of the project and are discussed in detail in the Best Practice Guide.
Data transfer to HPC-Site
When moving from academic usage, in which the application developer or even HPC-experts are directly involved in the execution of engineering applications on HPC resources, to production like usage scenarios, in which the user of the application is neither an HPC expert nor an application developer, it becomes essential to ease the usage of HPC systems especially during the preparation of the input and the compute tasks. This can also be of great benefit in the uptake of HPC methodologies by new stakeholders. In addition, data integrity & security throughout the development process are essential for industrial users to ensure short turnaround times and prevent duplicated efforts. In the course of the EXCELLERAT project, a solution and approach to circumvent these problems was developed.
Besides the elaborations in section 2.1 of the Best Practice Guide, the demonstration of a full engineering use-case’s data roundtrip based on the developed solution is described in both a white paper and the “Success Story: Enabling High Performance Computing for Industry through a Data Exchange & Workflow Portal”. While the white paper and success story give an overview, a more detailed description of the data transfer platform’s technical details, along with the description of its user interface and approaches to ensure secure and efficient data transfer, can be found in the EXCELLERAT deliverables D4.2 “Report on the Service Portfolio” in section 4.4 and D4.6 “Report on Enhanced Services Progress” in section 5.
Mesh generation for high order methods
In the industrial and productive usage of computer aided engineering and computational fluid dynamics, high order methods are only very rarely used. Even though they can deliver results of superior quality, one of the main bottlenecks of these methods is the preparation of suitable computational grids. This becomes a complex and time-consuming task once realistic geometries have to be handled. With Nek5000, a highly scalable and efficient HPC application of the aforementioned type was selected as a core code of EXCELLERAT. The developments and best practices for high order mesh generation based on gmsh and OpenCASCADE are described in detail in section 2.2 of the Best Practice Guide.
Given that the central step for all of the use-cases considered during the initial phase of EXCELLERAT was the simulation step, i.e. the execution of the simulation code on large scale HPC resources with the main targets being efficiency and scalability towards exascale readiness, most of the work of the EXCELLERAT team was focused on simulation covered in section 3 of the Best Practice Guide.
Adaptive mesh refinement
Since the data size used to discretize a simulation domain significantly grows once exascale simulations are targeted, one quickly finds that generating the needed meshes offline and transferring the data from the user site to the HPC centre is no longer efficient and at some point not even possible.
The strategy to circumvent the problem of high-resolution mesh generation is to generate lower resolved baseline meshes and then move the generation of the final, highly resolved computational mesh by so called mesh refinement “in core” i.e. to the HPC system. Another further step which can greatly increase the efficiency of the complete simulation step is to use adaptive mesh refinement techniques in which only the regions of the computational domain are refined. In this case, the targeted physical phenomena show high spatial variations. As this was one of the focus areas of the initial phase of EXCELLERAT, diverse strategies to implement AMR in simulation codes were pursued.
RWTH has developed AMR within their m-AIA application. They employ a regular octree mesh, and AMR is triggered based on phenomenon-based sensors embedded within the target simulations. Moreover, these sensors help to determine if mesh cells should be refined or coarsened.
BSC has parallelized their AMR workflow within their Alya application. Alya employs unstructured meshes using the gmsh mesher. The mesh is partitioned using Metis and an in-house space-filling curve (SFC) partitioner. The solver uses first- and second-order finite elements. Alya can be used to solve 3D incompressible Navier-Stokes flow, low Mach flow, multiphase flow, and combustion. Numerical schemes include low-dissipation numerical schemes for momentum and scalar transport, entropy-stable algorithm for multiphase flow based on a conservative level set, explicit time schemes, Runge-Kutta 3rd and 4th order, and Krylov subspace solution methods for the pressure solver.
CERFACS has created a new AMR process for their AVBP application, namely TREEADAPT. AVBP employs unstructured meshes using the gmsh icemcfd, centaur soft, and cfd-geom meshers. The mesh is partitioned using ParMETIS, Ptscotch, Metis, and an in-house implementation of RIB and RCB. The solver uses a combination of finite difference, finite elements and spectral elements in second- and third-order. The code can be used to solve 3D compressible Navier-Stokes flow, with LES for reactive flows. Numerical schemes include 2nd (Lax Wendroff) and 3rd order (Taylor Galerkin) explicit schemes. TREEADAPT was built on top of the hierarchical domain decomposition library TREEPART and is able to use the computing system topology for optimal parallel performance. Mesh adaptation itself is handled by the opensource package MMG, which is capable of adapting triangular and tetrahedral elements.
KTH describes the AMR spectral method application, Nek5000. The AMR method does not employ re-meshing but increases the number of degrees of freedom by increasing the element count. Nek5000 employs unstructured meshes using the following meshers: native simple tools; gmsh (supported converter gmsh2nek); additional supported converters from Exodus format (HEX20 in 3D and QUAD8 in 2D) and CGNS library (HEXA8, HEXA20 and HEXA27). The mesh is partitioned using ParMETIS, and an in-house parRSB partitioner. The solver uses spectral elements of up to 15th-order. Nek5000 can be used to solve 3D incompressible Navier-Stokes flow. Numerical schemes include time-stepping BDF/EXT; a pressure correction scheme witch staggered pressure points (PN-PN-2), and a 2-level additive Schwarz pre-conditioner for pressure equation.
The detailed best practices for the different approaches along with sources for further reading can be found in section 3.4 of the Best Practice Guide.
Discretisation Methods, Domain Decomposition and Solutions Strategies for Linear Systems of Equations
In addition, overviews of the knowledge gained as best practices in the areas upstream of adaptive mesh refinement, discretisation methods, and domain decomposition are presented in sections 3.1 and 3.2 of the Best Practice Guide. If implicit discretisation methods are used, then techniques for solving linear systems of equations are another important area which must be considered when scaling problems efficiently towards exascale. The insights gained in this area are summarised in section 3.3.
Load Balancing, Validation and Efficient I/O Strategies
A trade-off that of course comes along with the implementation of AMR methods is the unbalanced load distribution between the parallel processes arising from decomposition of the initial mesh and local refinements. This is why load balancing strategies were investigated in detail and the respective findings considered best practices are presented in section 3.5 of the Best Practice Guide. As all the aforementioned methods significantly improve the efficiency and scaling of the codes, they also introduce significant changes into the numerics of the codes. Due to that, validation and regression gets an even more important role as before. The corresponding best practices that were found by the EXCELLERAT consortium are presented in section 3.6.
As one can state that the movement of a problem towards large scale HPC is nowadays first of all the conversion of a compute or memory bound problem into an I/O bound problem, the best practices to circumvent this problem are presented in section 3.7 of the Best Practice Guide.
Once the simulation step i.e. the simulation code is executed or produces results, the output data have to be post-processed in order to be interpreted by either a domain expert or in case of e.g. an automatic optimization procedure an algorithm. In both cases, especially when data are stored on file systems or have to be transferred to another system or the user’s site, the first thing to do is to apply data reduction and compression algorithms. The findings and best practices with respect to this are presented in section 4.1 of the Best Practice Guide.
When targeting exascale applications, looking at the raw result data produced by the simulation fields is no longer the way to go even though visualization might be possible. Instead, a key methodology that has to be employed in order to evaluate and analyse the produced large-scale result data and to draw meaningful insights is HPDA. An overview of the best practices in this area can be found in section 4.2 of the Best Practice Guide. In turn, the visualization methods that were found to be best applicable in the case of exascale engineering applications, especially in combination with HPDA, are presented in section 4.4.
Since data transfer of input and result data from and to the user’s site is considered in pre- and post-processing steps, the focus is directed towards automatic workflow processing in the simulation workflow and result feedback step. In the first phase of EXCELLERAT, methods for uncertainty quantification were especially considered. The best practices in that area are detailed in section 5 of the Best Practice Guide.
In addition to the tasks that can directly be assigned to the individual steps of the engineering workflow, performance engineering and efficient implementation play an essential role in the use of HPC, especially when targeting the use of systems that consume several megawatts of electrical energy. Since this is true for all applications executed on large scale HPC resources independent of their position within the engineering workflow, these general activities and the best practices that were found when dealing with engineering applications are grouped together in section 6 of the Best Practice Guide. Besides best practices for node-level and system-level performance engineering in sections 6.1 and 6.3 respectively, the approaches taken when porting engineering applications to new architectures can be found in section 6.2.
As already mentioned, the Approach for extracting the most relevant areas on which to focus our efforts during the first phase of EXCELLERAT was to execute representative use-cases. Additionally, we gained the insight that especially academic users and application developers are interested in descriptions of best practices as a form of knowledge transfer. They then use these descriptions to find starting points and ideas for where to get more details and to quickly find out what works or doesn’t work in a given situation.
In this respect, one can state that a best practice for knowledge transfer for academic application users and developers is descriptions of best practices. Hence, EXCELLERAT will keep using this format because we have found it to be of great value especially but not exclusively for the academic community that deals with HPC in engineering.